
Physical Properties #2

Last week, we talked about the idea of physical properties, which are attributes of a result set that, in some sense, do not have bearing on whether that result set is a valid answer to a given query. Today, I want to talk about how these can actually show up in the query optimization process. Let's invent a query optimization problem for ourselves.
We have a table
abcwith the following properties. It has one million rows, and one thousand unique rows. We want to evaluate the query:
SELECT DISTINCT * FROM abc ORDER BY a, b, c
You might be able to see by inspection the two natural query plans we might use to evaluate this, assuming a traditional execution engine, and that we have no index on abc:
Option 1:
Sort(HashDistinct(Scan[abc]))
Option 2:
OrderedDistinct(Sort(Scan[abc]))
OrderedDistinct requires a sorted input, so we need to apply the sort for it. HashDistinct has no such restriction, and so we don't need to sort for it.
And given the statistical information I gave you about abc, you might suppose that option 1 is likely to be more performant, since it avoids having to sort a million rows, and only has to sort a thousand.
The question is, then, how do we structure the search process in our optimizer so that we can find both of these options to evaluate them? Physical properties are one key, and the other is our old friend the Principle of Optimality.
To recap, the Principle tells us that we can do all of our optimizations locally. If we have a query plan with two subtrees, it suffices for us to optimize each subtree and then combine those in an optimal way to arrive at a globally optimal solution.
In the case of query plans, this "optimization" comes in the form of selecting between alternative "physical" options for any given logical computation. How we generate those plan options is out of scope for this post, but in this case, we have an operator with two options:
HashDistinct, which uses memory proportional to the unique rows in its input, and has no requirements on that input, andOrderedDistinct, which uses constant memory, but requires its input to be ordered.
The trick is that when we try to optimize a given subtree, we don't just provide that subtree as input to our optimization procedure. We provide the subtree in addition to a set of physical properties we would like of the result.
But, recall that we have the ability to "enforce" any physical properties we like. That's their defining property. So why do we ask the expressions to provide them themselves? Well, because oftentimes they can do so more efficiently. If we had an index on abc that allowed us to scan in a,b,c order, we wouldn't need a sort at all, and could just get that order "naturally" from the expression.
Sometimes not, though! Sometimes we are happier to simply ask the expression for no properties at all and then enforce them ourselves. This is often the case when we are going to reduce the size of the result set via a filter or something. We want to do the right thing in both of those cases.
This is why it's important that the Cascades framework is top-down. It lets us accomplish this sort of thing in a clean way.
So, if our tree looks something like this:
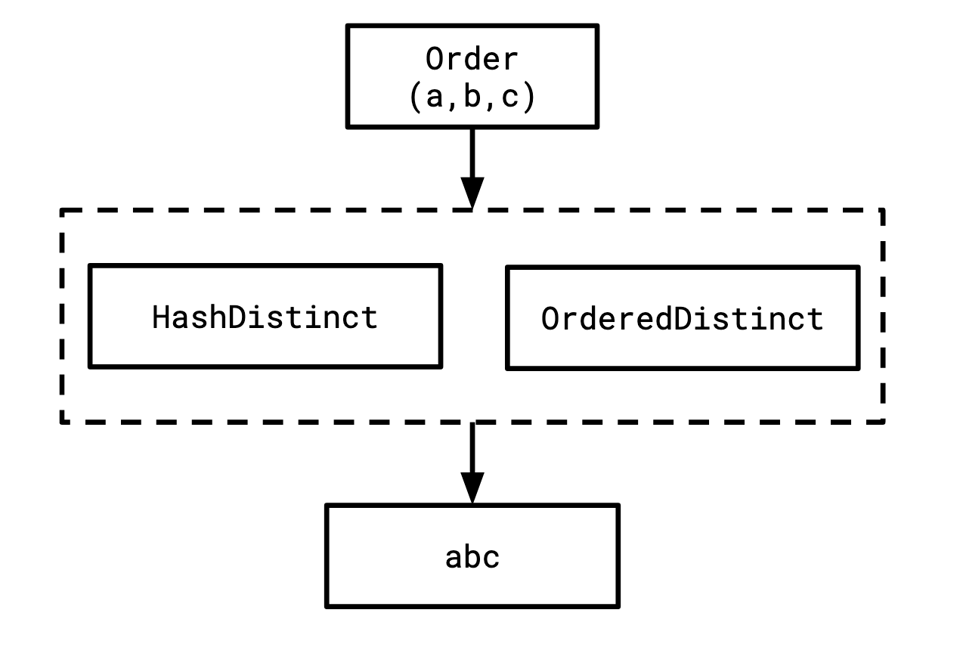
- We begin by attempting to optimize the
Ordernode at the top of the tree. This operator does nothing except require its input be ordered, as is necessary for the requested ordering on the original query. We then try to optimize the input logical distinct operation twice: once with the requested ordering, and once without. - We first optimize the input logical distinct operation with ordering. These logical collections of physical operators are called "groups." To optimize a group, we optimize each expression that constitutes it.
- We optimize
HashDistinct, asking it for ordered output. It then says, "okay, to get that, I need my input to be ordered. I can't provide it any other way." So it then tries to optimizeabcwith ordering. - Optimizing
abcwith ordering, since it has no indexes (if it did, we could model them as other members of a group, but since this group just has one member in this example we won't think of it as a group), will fail. - HashDistinct will then say, okay, now I will try to optimize
abcwithout ordering, and then add a sort enforcer below myself. - We optimize
abcwithout ordering. Since the empty set of physical properties is always satisfied, this will succeed. - Coming back up to the distinct group, we will now try to optimize OrderedDistinct with ordering. OrderedDistinct needs ordering on its input regardless of what it provides, so it will now optimize
abcwith ordering. - We already tried to optimize
abcwith ordering, so we will look this up in our memoization table and note that it failed. - Since that failed, OrderedDistinct will ask
abcfor no ordering, and then insert a sort enforcer itself to get the ordering required.
Checking in, we've now evaluated the following options (keep in mind we're tracking the estimated cost of all of these as we go):
HashDistinct(Sort(abc))
OrderedDistinct(Sort(abc))
- Now we pop back up to the top of the tree and again try optimizing the distinct operation with no required ordering (with the understanding that we'll insert a sort enforcer afterwards).
- We try optimizing the
HashDistinctwith no ordering requirement. It says fine, then tries to optimizeabcwith no ordering requirement. - We've already tried to optimize
abcwith no ordering requirement, so we simply defer to that computation we cached before. - We try optimizing the
OrderedDistinctwith no ordering requirement. It still needs the ordering on its input, so we repeat the computations from before.
Now we've evaluated the following options:
HashDistinct(Sort(abc))
OrderedDistinct(Sort(abc))
Sort(HashDistinct(abc))
Phew, that was a bit involved, but it's a bit of a subtle thing, where we need to evaluate each option in several different contexts. I hope that was helpful. Next week will be the final installment of this physical properties series.