507: quantum of sollazzo
#507: quantum of sollazzo – 28 February 2023
The data newsletter by @puntofisso.

Hello, regular readers and welcome new ones :) This is Quantum of Sollazzo, the newsletter about all things data. I am Giuseppe Sollazzo, or @puntofisso. I've been sending this newsletter since 2012 to be a summary of all the articles with or about data that captured my attention over the previous week. The newsletter is and will always (well, for as long as I can keep going!) be free, but you're welcome to become a friend via the links below.
The abstract of my keynote at csv,conf,v7, 19-21 April in Buenos Aires, has now been published. Here it is, ideas and feedback are still very much welcome.
Giuseppe self-describes as a "data jack-of-all-trades", and in this keynote he will walk through his data journey and tell some episodes with the lessons he learned. Current Deputy Director of the Artificial Intelligence Lab and Head of AI Skunkworks in the UK National Health Service, he was previously Head of Data at the UK Department for Transport, an IT and research computing lead in a medical school, a data wrangler, an open data activists, and he has been sending the weekly data newsletter "Quantum of Sollazzo" since 2012.
This keynote will give a light-hearted account of some of the common lessons learned while "talking with data" as a data wrangler, activist, and in central government. Here's a few highlights:
In 2014 Giuseppe created the Parli-N-Grams platform during a weekend hackathon. Mimicking Google Books Ngram Viewer, Parli-N-Grams is a website that shows the frequency over time of words used in debates in the UK Parliament. The platform has since acquired its own following, with its charts featured on the Financial Times, on ITV politics show "Peston On Sunday", and on the Sunday Times. The talk will reflect omn data standards, authoritative data, and the open data process in public authorities.
An Open Data activist at the high point of the governments interest in Open Data, Giuseppe joined a UK Government advisory panel on Open Data, and became so intertwined with advocacy that a colleague created a nickname for him: "the Open Data Rottweiler". The the talk will reflect on the sometimes delusional role of activism in data in a country like the United Kingdom, the need for a link between the data user community and the authorities, and the occasional fractious relationship among advocates of something as multi-faceted as data.
* Moving into leading data teams in central government and finding himself on the other side of the fence, Giuseppe was responsible for running NaPTAN, the UK national service that lists every bus stop and train station in the country. The talk will reflect on the management and evolution of an authoritative but collaborative dataset like NaPTAN, and explore questions related to data ethics and operationalisation from his recent work in AI in healthcare.
I was in Berlin last week, where I attended the first ever geomob Berlin. It was a brilliant event in many ways, but one thing has stuck more than others: the story that Ed told me about chatGPT.
TL;DR: someone asked chatGPT to produce a piece of Python code that does a reverse phone lookup using the OpenCageData(Ed's company and – full disclaimer – a previous sponsor of Quantum of Sollazzo) API. The code is legit and it runs.
With a little issue: OpenCageData does not offer a phone reverse lookup. This prompts two reflections.
The first is: from a technical point of view, I find it incredibly interesting to see something like this; it's wrong but also very right, in a certain, twisted, generative AI way. It is exactly as those graphic AI respond to a prompt like "draw me a portrait in the style of Van Gogh" with something that looks like a Van Gogh's painting but it's obviously not one. How did chatGPT get there? Apparently there are YouTube tutorials out there which seem to suggest that the API can do it, and chatGPT somehow must have learned from there.
The second reflection is on the psychosocial and economic impact of using AI to generate code. Ed is now dealing with a number of developers getting in touch to ask why his API doesn't work. Developers that, presumably, haven't even bothered checking the documentation, but blindly trusted chatGPT to give a correct answer. I don't necessarily blame them: AI is becoming pervasive and we're trusting it in increasingly subtle ways. Now, a geocoder is a relatively niche use case, and probably there won't be a sort of AI-driven DOS on OpenCageData's support service, but it's easy to see how wrong this might get.
If you want to read the full story, here's a blog post Don't believe ChatGPT - we do NOT offer a "phone lookup" service.
My friends at Open Ownership are looking for a Data Support Manager. Apply/recommend it to good candidates. Working with the legendary Thom Townsend is, believe me, a massive perk of this role.
The most clicked link last week was NPR's story about how climate change is threatening Saint-Louis.
'till next week,
Giuseppe @puntofisso
|
Become a Friend of Quantum of Sollazzo from $1/month → If you enjoy this newsletter, you can support it by becoming a GitHub Sponsor. Or you can Buy Me a Coffee. I'll send you an Open Data Rottweiler sticker. You're receiving this email because you subscribed to Quantum of Sollazzo, a weekly newsletter covering all things data, written by Giuseppe Sollazzo (@puntofisso). If you have a product or service to promote and want to support this newsletter, you can sponsor an issue. |
✨ Topical
Safe-district Democrats got more liberal. All Republicans got more conservative
The Washington Post reports on findings about the idological divide in US politics. There are quite a few great charts, some of which come from data in UCLA's VoteView, an incredibly rich website that explores and visualizes US electoral data.
The latter should remain accessible, should the Washington Post put the article behind a paywall.

How much money does the government spend per person?
USA Facts: "The US has responded to the past two recessions by increasing funding for federally administered programs."

The Post-Cold War Era Is Gone. A New Arms Race Has Arrived
"Countries around the world are drawing lessons from Europe’s first high-intensity war since 1945, reassessing everything from ammunition stocks to supply lines."

How long can Russia keep fighting the war in Ukraine?
TL;DR: "The bottom line: Putin’s war machine is under enormous pressure and could struggle to mount the decisive, new offensives that he has promised. But Russia has the resources to keep fighting in Ukraine for some time to come."
The Financial Times is tracking known levels of ammunition, public support, finances, etc.

The day the Earth moved
"How the Turkey earthquake tore a 300-kilometre rupture through the Earth’s surface".
It's fascinating how such data is now so broadly available.

Here Are the Buildings Reporting Fewer Regulated Apartments
"New data from housing group JustFix shows thousands of New York City apartments didn't register as rent-stabilized — even after a 2019 law required continued controls with few exceptions".
Besides the interactive map above, the story here is worth reading.

🛠️📖 Tools & Tutorials
PyGWalker
PyGWalker: "Turn your pandas dataframe into a Tableau-style User Interface for visual analysis".
It works on Jupyter notebooks.

pyCirclize
"Circular visualization in Python (Circos Plot, Chord Diagram)"

Visualizing Climate Change: A Step-by-Step Guide to Reproduce Climate Stripes with Python
"A quick Matplotlib tutorial to build a remarkable visualization".
We've seen it before, but it's always nice to see more attempts.

Vision-Based Rep Counting in the Wild
"A review of different approaches to vision-based repetition counting".
Think about all those camera apps that count nails, LEGO bricks, or gym apps that keep a tally of how many push-ups you've done.

rang: make ancient R code run again
A good thing for reproducibility: "The goal of rang is to obtain the dependency graph of R packages at a specific point in time. It can technically be used for similar purposes as renv, groundhog and others, but its main use case is as an “Rchaeological” tool, reconstructing historical R computational environments which have not been completely declared at that point in time.""

ggplot tricks
"The goal of this repository is to keep track of some neat ggplot2 tricks I’ve learned."
Quite a few useful ones in here, from chart generation to minor aesthetic fixes.


Get smarter every day
Every day Refind picks 5 articles that make you smarter, tailored to your interests. Loved by 100k+ curious minds.
Subscribe to get 5 links / day
🤯 Data thinking
How coding can change the very journalism we do
Anastasia Valeeva at Source: "From faster, replicable work to multi-story databases, here’s what I’m most excited about after my fellowship with a data team".
How to Report on Scientific Findings
"When news outlets report that new research studies prove something, they’re almost certainly wrong."
GIJN gives some tips on how to get it right.
📈Dataviz, Data Analysis, & Interactive
1 dataset 100 visualizations
From information design agency Ferdio: "Every time we turn a set of data into a visual depiction, hundreds of design choices have to be made to make the data tell the best story possible. Many of the choices are unconscious, often resulting in similar solutions. The obvious and uninspired. This project goes beyond common solutions and best practice. It demonstrates how even the simplest dataset can be turned into 100 proper data visualizations telling different stories, using very limited visual properties and assets."
They use a dataset that compares UNESCO World Heritage Sites in Scandinavia in 2004 and 2022.
(via Marco Cortella)

Jerry's Brain
"Imagine if you had all the things worth remembering over the past 24 years, some 493,000 items, all curated in one giant mind map."
From a book on... information overload.
(via Massimo Conte)

Star Tours
"There's always a bigger TSP."
I can only love a page that starts with a mention to the Travelling Salesman Problem. A research group at the University of Waterloo in Canada decided to give TSP a try at an intergalactic scale: "Using 3D astronomical data, we have created 12 instances of the TSP, ranging in size from 100 points up to 1.33 billion points. In these examples, star to star travel is measured by straight-line Euclidean distances in three-dimensional space, rounded to the nearest 1/10th parsec."

A primer on Foreign Direct Investment
"About a year ago, Russia invaded Ukraine. In the UN’s vote to condemn Russia’s invasion of Ukraine, 17 African countries abstained from the vote. Back then people started voicing concerns about Russia’s growing influence internationally and especially in Africa. This made me wonder about the scale of Russia’s investments internationally and I stumbled upon a concept that I knew little about — Foreign Direct Investment (FDI)."

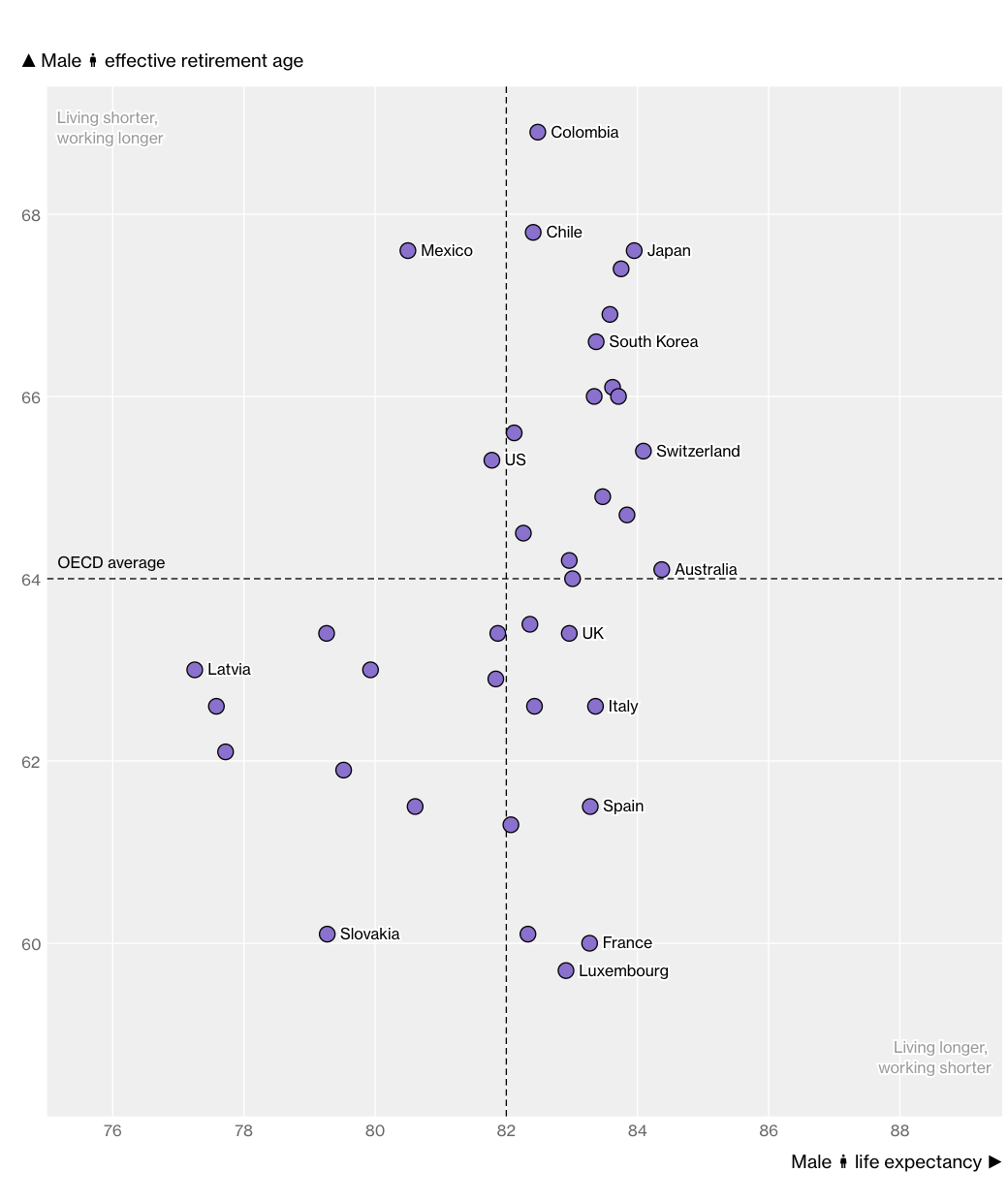
The Countries With the Longest — and Shortest — Retirements
"Even among major economies, the difference can be well over a decade."
Bloomberg takes a look with a few nice charts.
Patterns in the life of Vincent Van Gogh
"Vincent van Gogh's life was marked by turbulence, but he was also a prolific artist who created almost 900 oil paintings during his lifetime. In this data story, I aimed to reveal patterns in his work that emerge when we step back and examine his repertoire as a whole."
The link above is to the author's portfolio. The actual project seems to have gone offline as I write this, but will re-check later.

🤖 AI
phind
A search engine for developers, based on chatGPT... and of course, do go back to the introduction of this issue to see why this could go terribly wrong.
Massimo Conte also sends me this link to the Dunning-Krüger curve for chatGPT.

What Is ChatGPT Doing … and Why Does It Work?
Stephen Wolfram tries to explain.
quantum of sollazzo is supported by ProofRed's excellent proofreading. If you need high-quality copy editing or proofreading, head to http://proofred.co.uk. Oh, they also make really good explainer videos.

Supporters* casperdcl and iterative.ai Jeff Wilson Fay Simcock Naomi Penfold
[*] this is for all $5+/months Github sponsors. If you are one of those and don't appear here, please e-mail me