
Databases are not Compilers

Last week's issue was the topic of some contention in some of my circles. The general question was, is the following transformation valid:
SELECT count(*) FROM one_thousand INNER JOIN one_thousand ON random() < 0.5
into
SELECT
count(*)
FROM
(SELECT * FROM one_thousand WHERE random() < 0.5)
INNER JOIN
one_thousand ON true
Or the bolder
SELECT
count(*)
FROM
(SELECT * FROM one_thousand WHERE random() < 0.5)
INNER JOIN
(SELECT * FROM one_thousand WHERE random() < 0.5)
ON true
There were at least a couple people who were horrified that any database would move that call to random() at all—it's not a pure function! You have no right!
Well, I don't really have a strong opinion either way. Or like, I think you can argue either way pretty convincingly. The SQL spec might have an opinion on this but I don't think anyone cares that much what it says, that ship sailed a long time ago. I think there is value in discussing this, though.
I think that the argument for not moving the random() around kind of writes itself: it changes the visible behaviour of the program, so it's not a valid "optimization." This is like, compilers 101 stuff.
To be clear, the reason this is so bad is that one of the absolute worst-case outcomes for a query planner is that an update which adds or changes an optimization (which should be invisible, in theory) causes a query to error or behave differently than it did before.
I think that's a fine stance to take. On the other hand, I think there are some nonobvious considerations for why a default of being aggressive in these optimizations is good, and why some heuristics that come from compilers (which basically every programmer interacts with) maybe don't translate all the well to databases (which only most programmers interact with). My argument boils down to one main claim, which is that databases are not compilers.
First of all, SQL, from the get-go, doesn't have a notion of the execution order of things. Impure functions mess with that notion a bit, but the problem here is the impure functions—they're the culprit here.
Last week, I described a predicate pushdown by claiming that the following "transformation" is valid:
SELECT * FROM
abc
INNER JOIN
def
ON abc.a = def.d AND abc.b = 4
SELECT * FROM
(SELECT * FROM abc WHERE abc.b = 4)
INNER JOIN
def
ON abc.a = def.d
This was convenient but a little bit of an abuse of notation. Because I think one could very reasonably claim that talking about "transforming" SQL here as nonsensical: the SQL does not imply how the query is executed. That's the whole point! Two queries that are semantically equivalent (according to some semantics) are in fact just the same query in some sense. If you want to argue that moving the random() around changed the semantics of the query, you have to first argue that the location of the random() in the query suggests when it will be executed. Which is not especially clear!
Typically, in traditional programming languages, even functional ones that you might describe as "declarative," you're not specifying the "result" of the program, you're implementing an algorithm. This is why it's important that the language semantics and the compiler provide certain guarantees to you about what it's allowed to change, and this is why moving the random() around is so offensive to many: it's not doing what you told it to.
But there's an argument that it is doing what you told it. Because it wasn't actually all that meaningful that you happened to put the random() call where you did. To the SQL engine, those two things are as different as 1 + 2 and 2 + 1.
With genuinely declarative languages it's actually fairly important that you're not describing an algorithm, because the point is to protect the layers of the system above from knowing about the actual physical layout of data. The reason that the optimizer exists at the database level, rather than somewhere higher up, is so that queries can be generated at any level in the entire system and still be subject to optimization.

A vanishingly small amount of SQL is written by humans. Almost all of it is various compositions of dashboards, templates, ORMs, and inlined views that do not, and should not, have any opinions on how they will get executed. This is possible due to a very fundamental and incredibly valuable property of the relational model: it has what SICP calls the Closure Property. Queries are relations-in-relations-out, which makes them composable.
This is why it's so important to support "dumb" optimizations like pruning statically empty subtrees from UNION clauses, because queries are often generated without the context or machinery that would be needed to know that those subtrees are indeed empty.
I guess my point is that it's actually somewhat important, for the sake of machine generated SQL, that you can just like, slap a WHERE clause on at the top of a query and trust that it will make its way to the right place. This suggests to me that a default of "more optimization" is correct.
Ok, but, if I used an impure function like random(), doesn't that mean that I really care about its impurities? By using a function that is nondeterministic or has observable side effects, aren't I opting out of optimizations?
It turns out that in SQL, there's a lot of functions that care about when they're executed. Consider the following:
create table parts (part text);
insert into parts values ('day');
SELECT date_part(part, TIMESTAMP '2001-02-16 20:38:40') FROM parts;
The above runs completely fine in Postgres, and outputs, as expected,
16
But if we change the data (notably not something Postgres can infer from the query itself):
create table parts (part text);
insert into parts values ('bad');
SELECT date_part(part, TIMESTAMP '2001-02-16 20:38:40') FROM parts;
We get a runtime error:
ERROR: timestamp units "bad" not recognized
This is a very benign-looking SQL function, and if you were to say "it cannot be moved around because it has observable side effects," you'd be opting out of very likely safe and important optimizations.
How important? A favourite paper of mine, hugejoins.pdf (I know that's not the real name but that's all I can remember it as) remarks in its opening paragraph that they are aware of a real-world query with over 4000 relations joined. That kind of query is not written by hand, of course, it's the kind of machine generated, view-expanded monstrosity we talked about before.
Consider a query with the following shape:
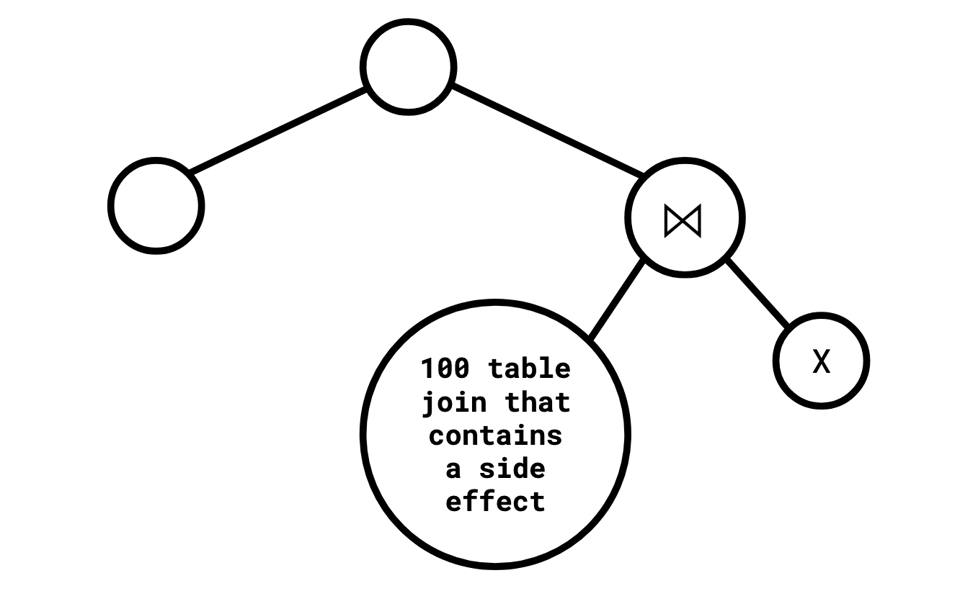
Should the database be obliged to keep around the subtree on the right if it can statically determine that X is empty (and thus the whole subtree is empty)? I think the answer from a compilers perspective is probably "yes," but the answer from a databases perspective is arguably "no."
I did say that one of the worst-case outcomes for a query planner is that a query breaks on a version upgrade. Unfortunately, it's not just erroring that can go wrong in such a situation. In any sufficiently widely-used query planner, I think pretty much any non-trivial change will be problematic to someone. See this earlier post of mine for more detailed thoughts.
Like I said, I do think both sides here are defensible. If you have strong convictions one way or the other I'd be curious to hear about them.