Git's UML/data model: Understand Git's state so you don't have to memorize/guess its commands
type Commit
= { tree: Tree
, parents: Array<Commit>
, commitMessage: string
// other stuff like commiter name, commit date, ... etc.
};
type Tree // A fancy name for a directory/folder
= { children: Array<{name: string, child: Blob | Tree}> };
type Blob // A fancy name for a file
= string; // the contents of the file
What this says in human terms: A commit stores the state of filesystem, not the difference between it and its parent commit. Also, there's absolutely no relation between a commit's state of filesystem and its parent commits' -- you could have a merge commit (a commit with more than one parent) have a filesystem state totally unrelated to any of its parent commits' -- not to even mention what we conceptually think of as a "merge".
Then, why doesn't .git/ directory size keep increasing by much with each commit? ... Answer: Compression/Implementation detail.
class Commit {Tree* tree; Commit** parent;} was such a mindset shift for me. (C++ representation of the same idea).
What about the commands revert, diff, and others? ... They're synthetic commands - helpers on top of the Git data model. But they are in no way essential to understanding Git.
Iteration#2: Branches, and matching the reality better
What about branches and the strange ab8ef31... commit ids?
Git's .git/ directory is a database after all (but not a relational one/table-based one. Object-based and stores objects in files). There're no Java/TypeScript-like object references, it's all ids.
type ObjectType
= 'Blob' // a file
| 'Tree' // a directory/folder
| 'Commit'
// | 'Tag' // out-of-scope.
type Commit
= { objectId: string
, type: 'Commit',
, tree: string // object id of tree object of this commit
, parents: Array<string> // parent commits' object ids
// other stuff like commiter name, commit date, ... etc.
};
type Tree // A fancy name for a directory/folder
= { objectId: string
, type: 'Tree'
, children: Array<{name: string, child: string}> // child is object id of child file/blob or tree/directory.
};
type Blob // A fancy name for a file
= { objectId: string
, type: 'Blob'
, content: string
};
type Branch
= string; // the object-id of the commit it's pointing to. Nothing more!
Wanna see for yourself?
Go open .get/refs/heads/master file in your repository. You'll see all it contains is a commit id!
(Will use my now-failed project, Transparent Salaries for examples)
Here's a screenshot:

Want to see a commit for yourself?
Now go run git cat-file -p 3cfbbd707b37a970cb02aa46a5ea9024ffc76057 (or use any other commit id).
In Git: commits, directories, and files, are all what Git calls objects with type and an id, or files but in this Git unusual filesystem (Yes, this bit is not clarified yet).
What git cat-file -p does is that it basically pretty-prints the object.
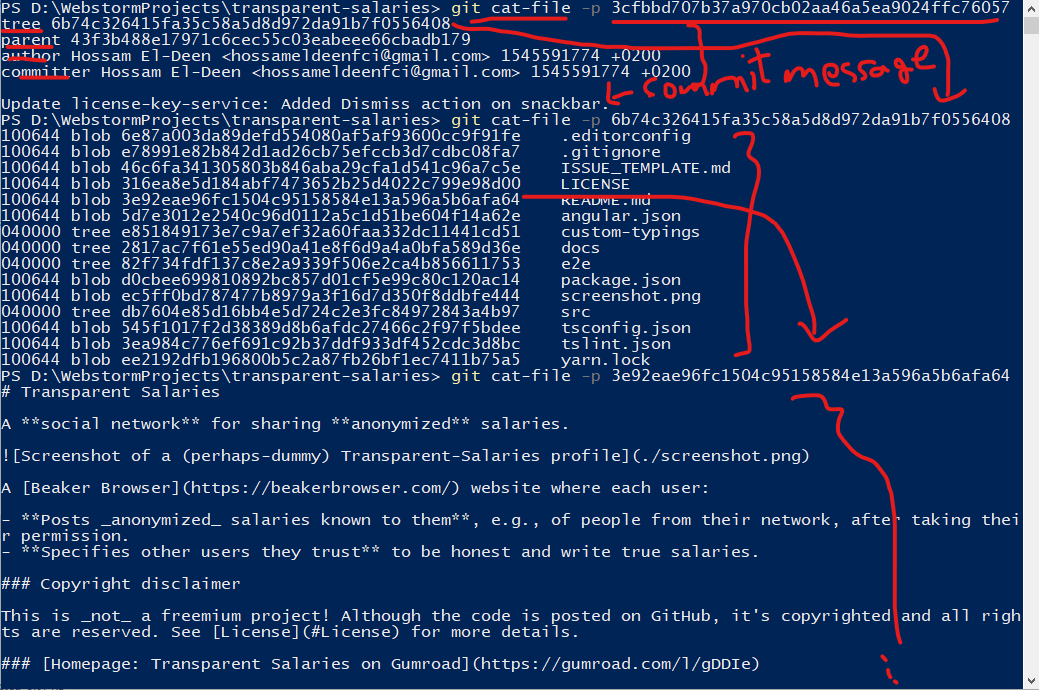
Or perhaps, better formatted:

In the picture above:
- The commit id of some commit. (I got the one from
.git/refs/heads/masterat the time of writing). - The contents of the commit. You'll see it has
tree <objectIdOfFileSystemAtThisCommit>,parent <objectIfOfParentCommit>, some metadata like author name, ... etc.
git cat-fileknew that this is a commit and printed it that way because the object3cfbbd707b37a970cb02aa46a5ea9024ffc76057has the typeCommit. - Part also of the commit metadata. This was the commit message.
- I copied the id of the
treeof the printed commit and pasted it here. - List of files/directories in commit's tree (i.e., root directory of the repo at the time of the commit).
This is just a pretty-print. E.g., the type of the child is probably not part of the tree, but part of the child. I don't know what the leftmost column is - Took the id of
README.mdand pasted it here. - The contents of
README.md!
A takeaway: For all purposes, a branch is the same as a commit!
There's no such thing as a branch -- actually, Git is a Directed Acyclic Graph, not a tree, even. And a branch is merely is a pointer to a commit, it has no extra info about, e.g., the ancestor commits, than the commit. All that info is in the commit (with its parents list).
Iteration#3: Power with git reflog
If you delete a branch (e.g., from IntelliJ's Version-Control tab) and no other branch was pointing to the commit or any of descendants, you'll see it gone from the UI! Did you just lose your work?!
Luckily, Git keeps the commits for sometime even if no branch is referencing them -- think of it like garbage before garbage collection happens.
But how would know what the commit's id was?!
Most luckily *ba2a* (as we say in Arabic) is the git reflog command. It prints the history of a branch!
I don't have a repo at the moment to show it well with. So, instead, here's a page from Julia Evans's Dangit, git! zine!

You can also see for yourself where Git stores this info! ... Go open .git/logs/refs/heads/master in any of your repos!
Update: I've showed this to a friend and he thought I meant the, e.g., Log tab in IntelliJ's Version Control. That's not it!
It's about what happens when you, e.g., reset a branch from commit X to commit Y and now the commit X is gone from IntelliJ's Log. What git reflog <branch> does is listing what the branch was pointing before what it's pointing to now. So, you can use that info to get the commit id of X and create a new branch to (or have an existing one) point to it.
A quick look at .git/

hooks/: You can put here scripts to run automatically after/before commit/push, ... etc. Not so different from maven or npm lifecycle hooks.info/: I don't know.logs/: Stores the history of what a branch was pointing to. Forgit reflog. Check it out yourself.objects/: The objects (commits, trees/directories, and blobs/files). That it doesn't stores the objects in files directly underobjects/but under intermediate directories (e.g.,e9) is an implementation due to some historical (or non-historical) limits on the number of files in a directory or something.
If you have just cloned a repo, odds are you'll only findinfo/andpacks/. Packfile is a compression format of git objects. Don't know whatobjects/infois, though.refs/: The branches. See for yourself.
For therefs/tags/directory, some tags are refs and some tags are objects. Out-of-scope anyway.config/: Some key values likeauthor.emailand configuration like CRLF stuff.
What has not been covered
- What is this
HEADbranch? - Remotes (Hint: see
.git/refs/remotes. Anorigin/masteris merely a cache of themastervalue last timegit fetchhappened.git pull origin masteris merelygit fetch && git merge origin/master(to mergeorigin/masterinto current branch). Commands here are pseudo-code, haven't actually tried them). - Use-cases: rebase - abort merge - resolve conflicts - revert - restore lost work (reflog), ... etc.
- Hashes: Why Git is a Directed Acyclic Graph and not just a graph (Hint: The objects' ids are hashes of their content, including the references they have to other objects. This makes it (1) impossible to have cycles, try to create one yourself, and (2) the objects are immutable: can't have an id point to an object and then point to a different one, because an id is a function of the object)
Git's comforting thoughts
-
Git's data model is immutable: You can't edit a commit, tree, or a file. You can only create new ones.
-
Git's commit has the current state, doesn't depend on the history.
-
Hard to lose something by playing with branches: As long as you've committed it, you can
git reflogand find it again. (on the same machine, at least. But can't help you by much if you delete your directory and haven't pushed your changes). -
Haven't covered it: But not much of a difference between a local and a remote branch. You can, e.g.,
git difforgit mergewithorigin/foo. A remote branch is merely the value of the branch on the remote server last timegit fetchwas run.
Disclaimers
- For literary purposes (or otherwise), I may not have described everything accurately. Or may have made mistakes.
- I'm not responsible for anything in this article. Read on your own risk.
Privacy notes
- Buttondown tracks who opens, clicks, or forwards my emails, and shares this data with me. If you want to delete this data, email me and I'll try my best!
- Buttondown adds "UTM sources" to my links to let websites I've linked to know that the source of the new traffic is my newsletter (as far as I understand).
- Buttondown gives me the choice to opt out of both points above, but I've chosen to opt in.
Copyright
This is an All-Rights Reserved work. Please, don't rehost it.
Linking to it is naturally allowed (and appreciated!), but rehosting is not. Reasonable sharing like forwarding to a few friends or a quote screenshot is fair use, I believe.
You can reply directly to this email.