Malleable software in the age of LLMs
All computer users may soon have the ability to author small bits of code. What structural changes does this imply for the production and distribution of software?

It's been a wild few weeks for large language models. OpenAI released GPT-4, which shows impressive gains on a variety of capabilities including coding. Microsoft Research released a paper showing how GPT-4 was able to produce quite sophisticated code like a 3D video game without much prompting at all. OpenAI also released plugins for ChatGPT, which are a productized version of the ReAct tool usage pattern I played around with in my previous post about querying NBA statistics using GPT.
Amid all this chaos, many people are naturally wondering: how will LLMs affect the creation of software?
One answer to that question is that LLMs will make skilled professional developers more productive. This is a safe bet since GitHub Copilot has already shown it's viable. It's also a comforting thought, because developers can feel secure in their future job prospects, and it doesn't suggest structural upheaval in the way software is produced or distributed 😉
However, I suspect this won't be the whole picture. While I'm confident that LLMs will become useful tools for professional programmers, I also think focusing too much on that narrow use risks missing the potential for bigger changes ahead.
Here's why: I think it's likely that soon all computer users will have the ability to develop small software tools from scratch, and to describe modifications they'd like made to software they're already using. In other words, LLMs will represent a step change in tool support for end-user programming: the ability of normal people to fully harness the general power of computers without resorting to the complexity of normal programming. Until now, that vision has been bottlenecked on turning fuzzy informal intent into formal, executable code; now that bottleneck is rapidly opening up thanks to LLMs.
If this hypothesis indeed comes true, we might start to see some surprising changes in the way people use software:
- One-off scripts: Normal computer users have their AI create and execute scripts dozens of times a day, to perform tasks like data analysis, video editing, or automating tedious tasks.
- One-off GUIs: People use AI to create entire GUI applications just for performing a single specific task—containing just the features they need, no bloat.
- Build don't buy: Businesses develop more software in-house that meets their custom needs, rather than buying SaaS off the shelf, since it's now cheaper to get software tailored to the use case.
- Modding/extensions: Consumers and businesses demand the ability to extend and mod their existing software, since it's now easier to specify a new feature or a tweak to match a user's workflow.
- Recombination: Take the best parts of the different applications you like best, and create a new hybrid that composes them together.
All of these changes would go beyond just making our current software production process faster. They would be changing when software gets created, by whom, for what purpose.
LLMs + malleable software: a series
Phew, there's a lot to unpack here. 😅
In a series of posts starting with this one, I'll dig in and explore these kinds of broad changes LLMs might enable in the creation and distribution of software, and even more generally in the way people interact with software. Some of the questions I'll cover include:
- Interaction models: Which interaction model will make sense for which tasks? When will people want a chatbot, a one-off script, or a custom throwaway GUI?
- Software customization: How might LLMs enable malleable software that can be taken apart, recombined, and extended by users?
- Intent specification: How will end-users work interactively with LLMs to specify their intent?
- Fuzzy translators: How might the fuzzy data translation capabilities of LLMs enable shared data substrates which weren't possible before?
- User empowerment: How should we think about empowerment and agency vs delegation and automation in the age of LLMs?
When to chatbot, when to not?
Today, we'll start with a basic question: how will user interaction models evolve in the LLM era? In particular, what kinds of tasks might be taken over by chatbots? I think the answer matters a lot when we consider different ways to empower end-users.
As a preview of where this post is headed: I'll argue that, while ChatGPT is far more capable than Siri, there are many tasks which aren't well-served by a chat UI, for which we still need graphical user interfaces. Then I'll discuss hybrid interaction models where LLMs help us construct UIs.
By the end, we'll arrive at a point in the design space I find intriguing: open-ended computational media, directly learnable and moldable by users, with LLMs as collaborators within that media. And at that point this weird diagram will make sense 🙃:
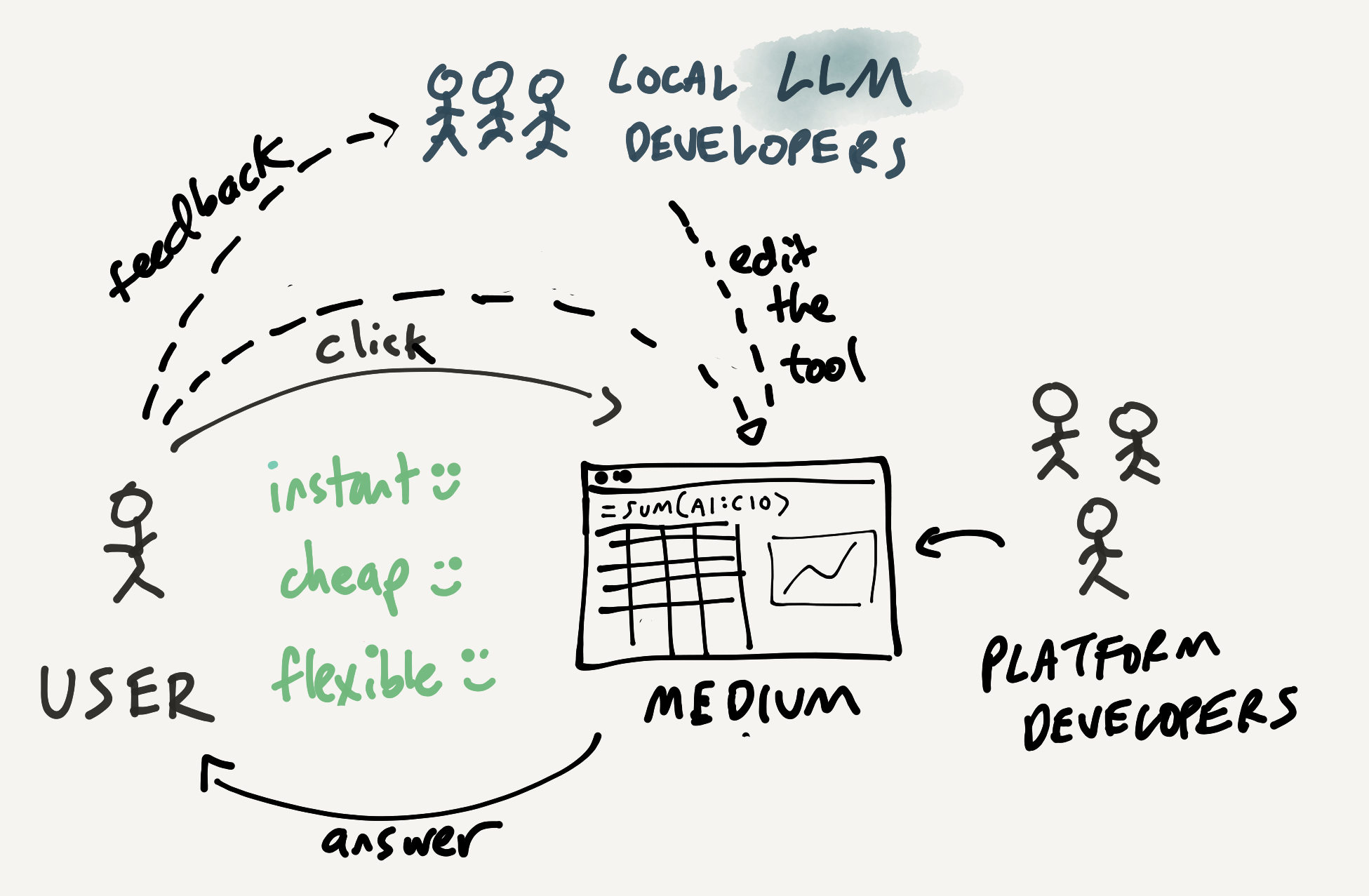
One disclaimer before diving in: expect a lot of speculation and uncertainty. I'm not even trying to predict how fast these changes will happen, since I have no idea. The point is to imagine how a reasonable extrapolation from current AI might support new kinds of interactions with computers, and how we might apply this new technology to maximally empower end-users.
Opening up the programming bottleneck
Why might LLMs be a big deal for empowering users with computation?
For decades, pioneers of computing have been reaching towards a vision of end-user programming: normal people harnessing the full, general power of computers, not just using prefabricated applications handed down to them by the programmer elite. As Alan Kay wrote in 1984: "We now want to edit our tools as we have previously edited our documents."
There are many manifestations of this idea. Modern examples of end-user programming systems you may have used include spreadsheets, Airtable, Glide, or iOS Shortcuts. Older examples include HyperCard, Smalltalk, and Yahoo Pipes. (See this excellent overview by my collaborators at Ink & Switch for a historical deep dive)
Although some of these efforts have been quite successful, until now they've also been limited by a fundamental challenge: it's really hard to help people turn their rough ideas into formal executable code. System designers have tried super-high-level languages, friendly visual editors and better syntax, layered levels of complexity, and automatically generating simple code from examples. But it's proven hard to get past a certain ceiling of complexity with these techniques.
Here's one example of the programming bottleneck in my own work. A few years ago, I developed an end-user programming system called Wildcard which would let people customize any website through a spreadsheet interface. For example, in this short demo you can see a user sorting articles on Hacker News in a different order, and then adding read times to the articles in the page, all by manipulating a spreadsheet synced with the webpage.
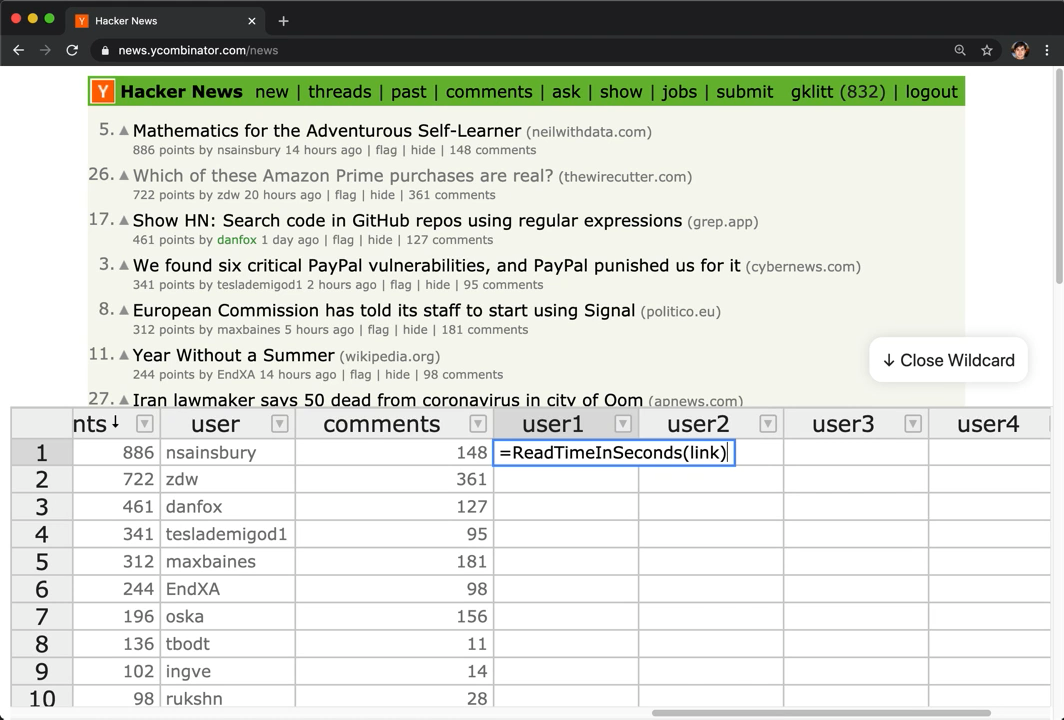
But if you look closely, there are two slightly awkward programming bottlenecks in this system. First, the user needs to be able to write small spreadsheet formulas to express computations. This is a lot easier than learning a full-fledged programming language, but it's still a barrier to initial usage. Second, behind the scenes, Wildcard requires site-specific scraping code (excerpt shown below) to connect the spreadsheet to the website. In theory these adapters could be written and maintained by developers and shared among a community of end-users, but that's a lot of work.
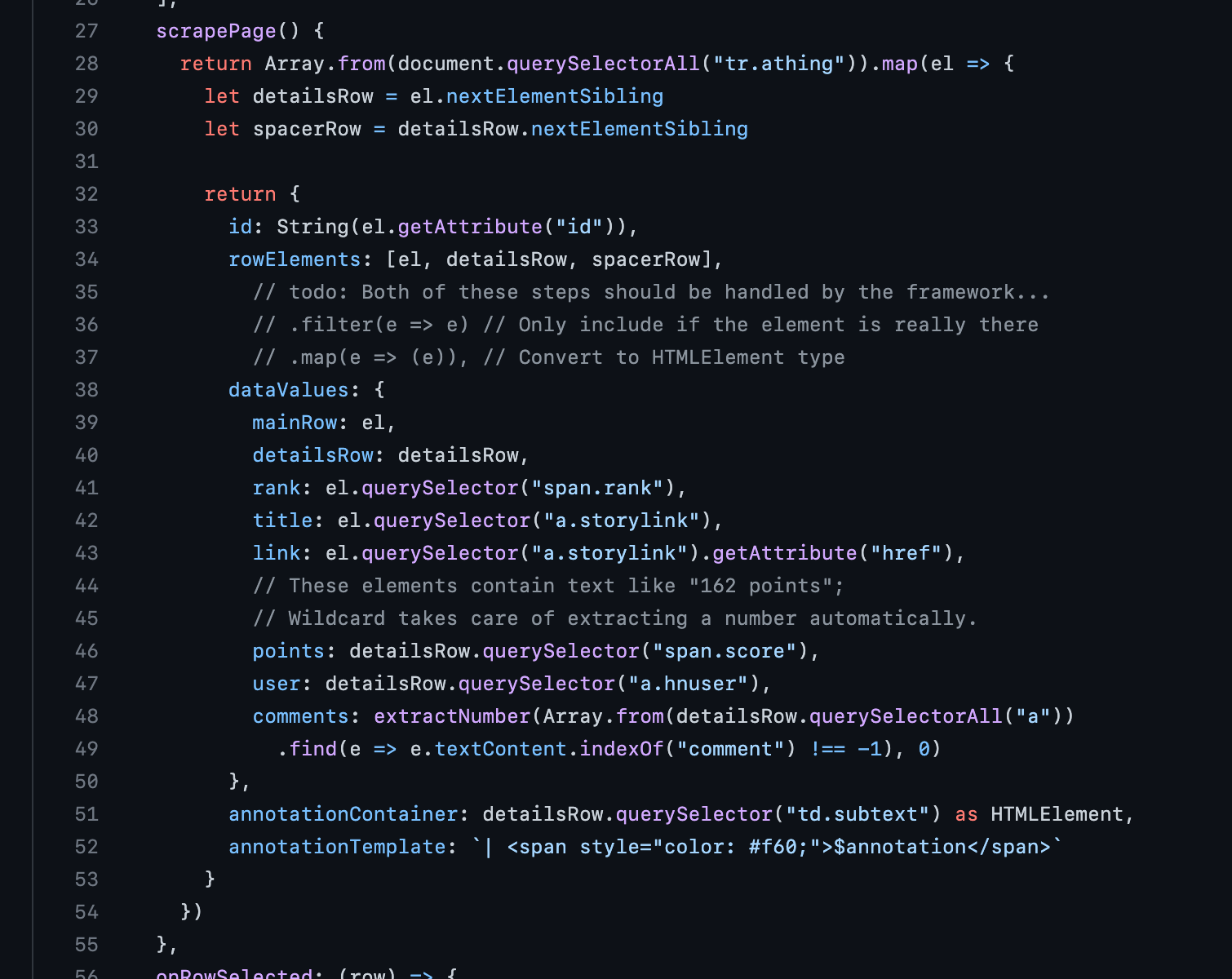
Now, with LLMs, these kinds of programming bottlenecks are less of a limiting factor. Turning a natural language specification into web scraping code or a little spreadsheet formula is exactly the kind of code synthesis that current LLMs can already achieve. We could imagine having the LLM help with scraping code and generating formulas, making it possible to achieve the demo above without anyone writing manual code. When I made Wildcard, this kind of program synthesis was just a fantasy, and now it's rapidly becoming a reality.
This example also suggests a deeper question, though. If we have LLMs that can modify a website for us, why bother with the Wildcard UI at all? Couldn't we just ask ChatGPT to re-sort the website for us and add read times?
I don't think the answer is that clear cut. There's a lot of value to seeing the spreadsheet as an alternate view of the underlying data of the website, which we can directly look at and manipulate. Clicking around in a table and sorting by column headers feels good, and is faster than typing "sort by column X". Having spreadsheet formulas that the user can directly see and edit gives them more control.
The basic point here is that user interfaces still matter. We can imagine specific, targeted roles for LLMs that help empower users to customize and build software, without carelessly throwing decades of interaction design out the window.
Next we'll dive deeper into this question of user interfaces vs. chatbots. But first let's briefly go on a tangent and ask: can GPT really code?
Cmon, can it really code though?
How good is GPT-4's coding ability today? It's hard to summarize in general terms. The best way to understand the current capabilities is to see many positive and negative examples to develop some fuzzy intuition, and ideally to try it yourself.
It's not hard to find impressive examples. Personally, I've had success using GPT-4 to write one-off Python code for data processing, and I watched my wife use ChatGPT to write some Python code for scraping data from a website. A recent paper from Microsoft Research found GPT-4 could generate a sophisticated 3D game running in the browser, with a zero-shot prompt (shown below).

It's also not hard to find failures. In my experience, GPT-4 still gets confused when solving relatively simple algorithms problems. I tried to use it the other day to make a React application for performing some simple video editing tasks, and it got 90% of the way there but couldn't get some dragging/resizing interactions quite right. It's very far from perfect. In general, GPT-4 feels like a junior developer who is very fast at typing and knows about a lot of libraries, but is careless and easily confused.
Depending on your perspective, this summary might seem miraculous or underwhelming. If you're skeptical, I want to point out a couple reasons for optimism which weren't immediately obvious to me.
First, iteration is a natural part of the process with LLMs. When the code doesn't work the first time, you can simply paste in the error message you got, or describe the unexpected behavior, and GPT will adjust. For one example, see this Twitter thread where a designer (who can't write game code) creates a video game over many iterations. There were also some examples of iterating with error messages in the GPT-4 developer livestream. When you think about it, this mirrors the way humans write code; it doesn't always work on the first try.
A joke that comes up often among AI-skeptical programmers goes something like this: "Great, now no one will have to write code, they'll only have to write exact, precise specifications of computer behavior..." (implied: oh wait, that is code!) I suspect we'll look back on this view as short-sighted. LLMs can iteratively work with users and ask them questions to develop their specifications, and can also fill in underspecified details using common sense. This doesn't mean those are trivial challenges, but I expect to see progress on those fronts. I've already had success prompting GPT-4 to ask me clarifying questions about my specifications.
Another important point: GPT-4 seems to be a lot better than GPT-3 at coding, per the MSR paper and my own limited experiments. The trend line is steep. If we're not plateauing yet, then it's very plausible that the next generation of models will be significantly better once again.
Coding difficulty varies by context, and we might expect to see differences between professional software engineering and end-user programming. On the one hand, one might expect end-user programming to be easier than professional coding, because lots of tasks can be achieved with simple coding that mostly involves gluing together libraries, and doesn't require novel algorithmic innovation.
On the other hand, failures are more consequential when a novice end-user is driving the process than when a skilled programmer is wielding control. The skilled programmer can laugh off the LLM's silly suggestion, write their own code, or apply their own skill to work with the LLM to debug. An end-user is more likely to get confused or not even notice problems in the first place. These are real problems, but I don't think they're intractable. End-users already write messy buggy spreadsheet programs all the time, and yet we somehow muddle through—even if that seems offensive or perhaps even immoral to a correctness-minded professional software developer.
Chat is an essentially limited interaction
Now, with those preliminaries out of the way, let's move on to the main topic of this post: how will interaction models evolve in this new age of computing? We'll start by assessing chat as an interaction mode. Is the future of computing just talking to our computers in natural language?
To think clearly about this question, I think it's important to notice that chatbots are frustrating for two distinct reasons. First, it's annoying when the chatbot is narrow in its capabilities (looking at you Siri) and can't do the thing you want it to do. But more fundamentally than that, chat is an essentially limited interaction mode, regardless of the quality of the bot.
To show why, let's pick on a specific example: this tweet from OpenAI's Greg Brockman during the ChatGPT Plugins launch this week, where he uses ChatGPT to trim the first 5 seconds of a video using natural language:
https://twitter.com/gdb/status/1638971232443076609
On the one hand, this is an extremely impressive demo for anyone who knows how computers work, and I'm excited about all the possibilities it implies.
And yet... in another sense, this is also a silly demo, because we already have direct manipulation user interfaces for trimming videos, with rich interactive feedback. For example, consider the iPhone UI for trimming videos, which offers rich feedback and fine control over exactly where to trim. This is much better than going back and forth over chat saying "actually trim just 4.8 seconds please"!
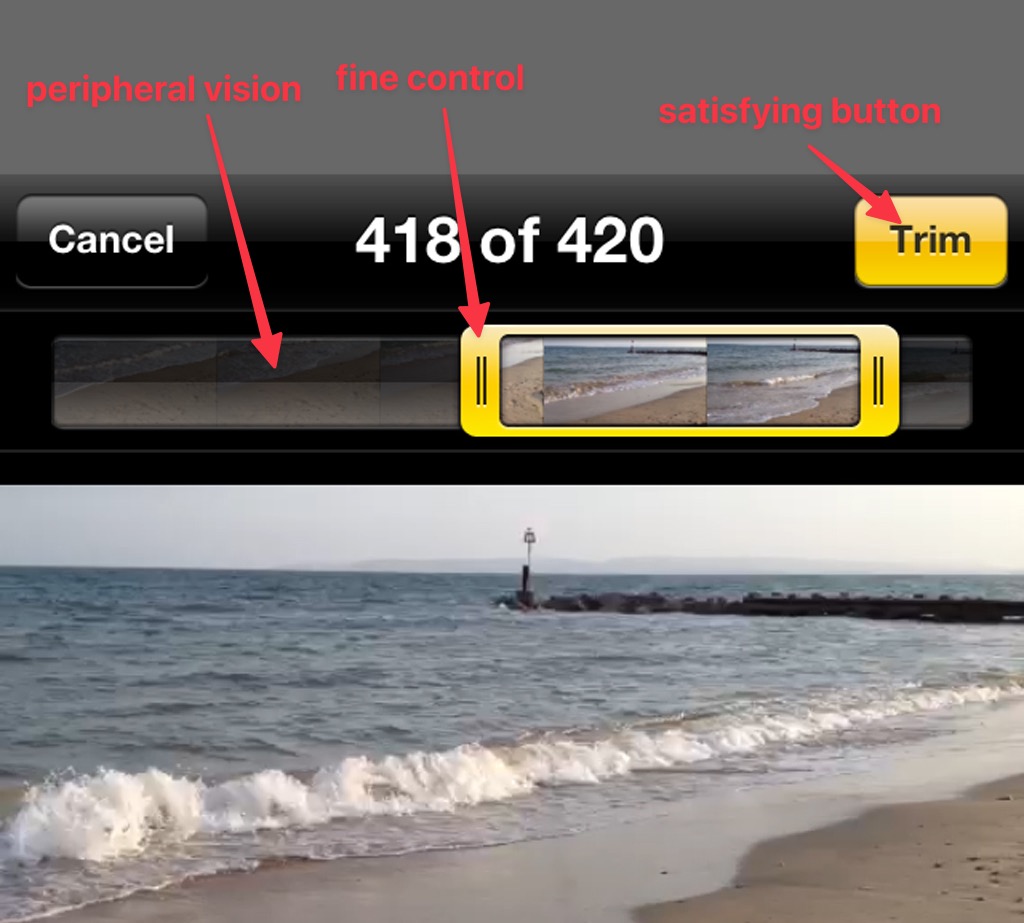
Now, I get that the point of Greg's demo wasn't just to trim a video, it was to gesture at an expanse of possibilities. But there's still something important to notice here: a chat interface is not only quite slow and imprecise, but also requires conscious awareness of your thought process.
When we use a good tool—a hammer, a paintbrush, a pair of skis, or a car steering wheel—we become one with the tool in a subconscious way. We can enter a flow state, apply muscle memory, achieve fine control, and maybe even produce creative or artistic output. Chat will never feel like driving a car, no matter how good the bot is. In their 1986 book Understanding Computers and Cognition, Terry Winograd and Fernando Flores elaborate on this point:
In driving a car, the control interaction is normally transparent. You do not think "How far should I turn the steering wheel to go around that curve?" In fact, you are not even aware (unless something intrudes) of using a steering wheel...The long evolution of the design of automobiles has led to this readiness-to-hand. It is not achieved by having a car communicate like a person, but by providing the right coupling between the driver and action in the relevant domain (motion down the road).
Consultants vs apps
Let's zoom out a bit on this question of chat vs direct manipulation. One way to think about it is to reflect on what it's like to interact with a team of human consultants over Slack, vs. just using an app to get the job done. Then we'll see how LLMs might play in to that picture.
So, imagine you want to get some metrics about your business, maybe a sales forecast for next quarter. How do you do it?
One approach is to ask your skilled team of business analysts. You can send them a message asking your question. It probably takes hours to get a response because they're busy, and it's expensive because you're paying for people's time. Seems like overkill for a simple task, but the key benefit is flexibility: you're hoping that the consultants have a broad, general intelligence and can perform lots of different tasks that you ask of them.
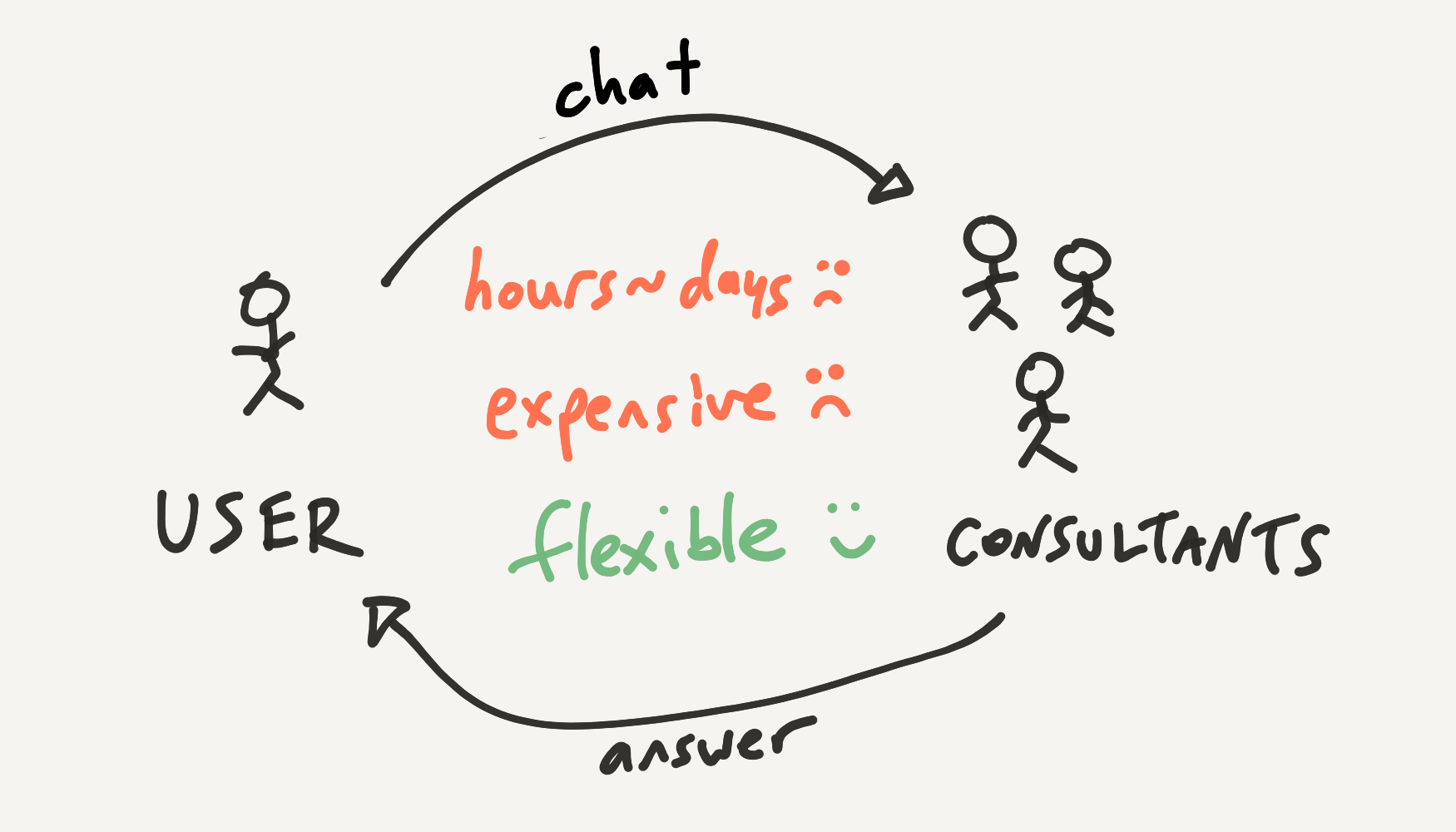
In contrast, another option is to use a self-serve analytics platform where you can click around in some dashboards. When this works, it's way faster and cheaper than bothering the analysts. The dashboards offer you powerful direct manipulation interactions like sorting, filtering, and zooming. You can quickly think through the problem yourself.
So what's the downside? Using the app is less flexible than working with the bespoke consultants. The moment you want to perform a task which this analytics platform doesn't support, you're stuck asking for help or switching to a different tool. You can try sending an email to the developers of the analysis platform, but usually nothing will come of it. You don't have a meaningful feedback loop with the developers; you're left wishing software were more flexible.
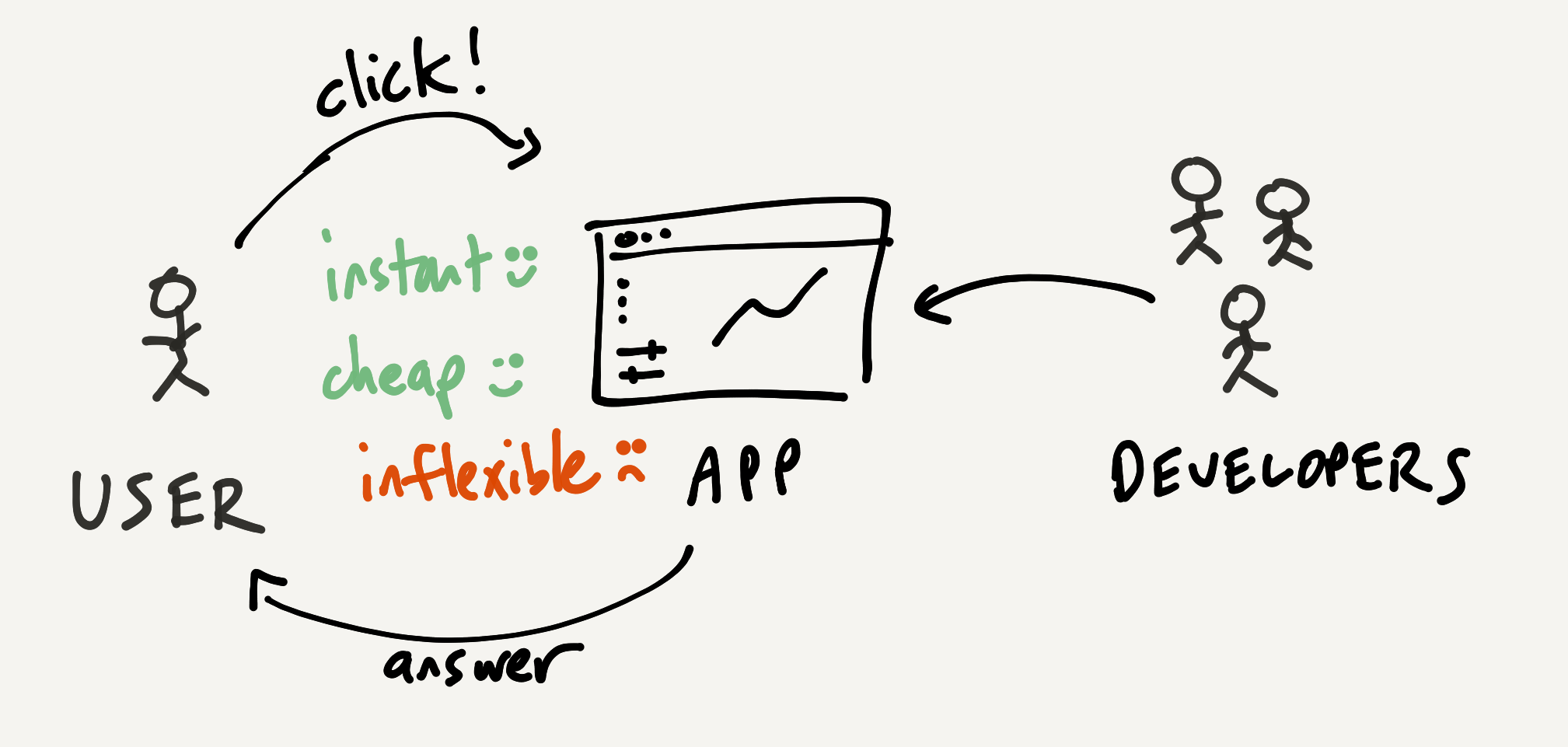
Now with that baseline comparison established, let's imagine how LLMs might fit in.
Assume that we could replace our human analyst team with ChatGPT for the tasks we have in mind, while preserving the same degree of flexibility. (This isn't true of today's models, but will become increasingly true to some approximation.) How would that change the picture? Well, for one thing, the LLM is a lot cheaper to run than the humans. It's also a lot faster at responding since it's not busy taking a coffee break. These are major advantages. But still, dialogue back and forth with it takes seconds, if not minutes, of conscious thought—much slower than feedback loops you have with a GUI or a steering wheel.
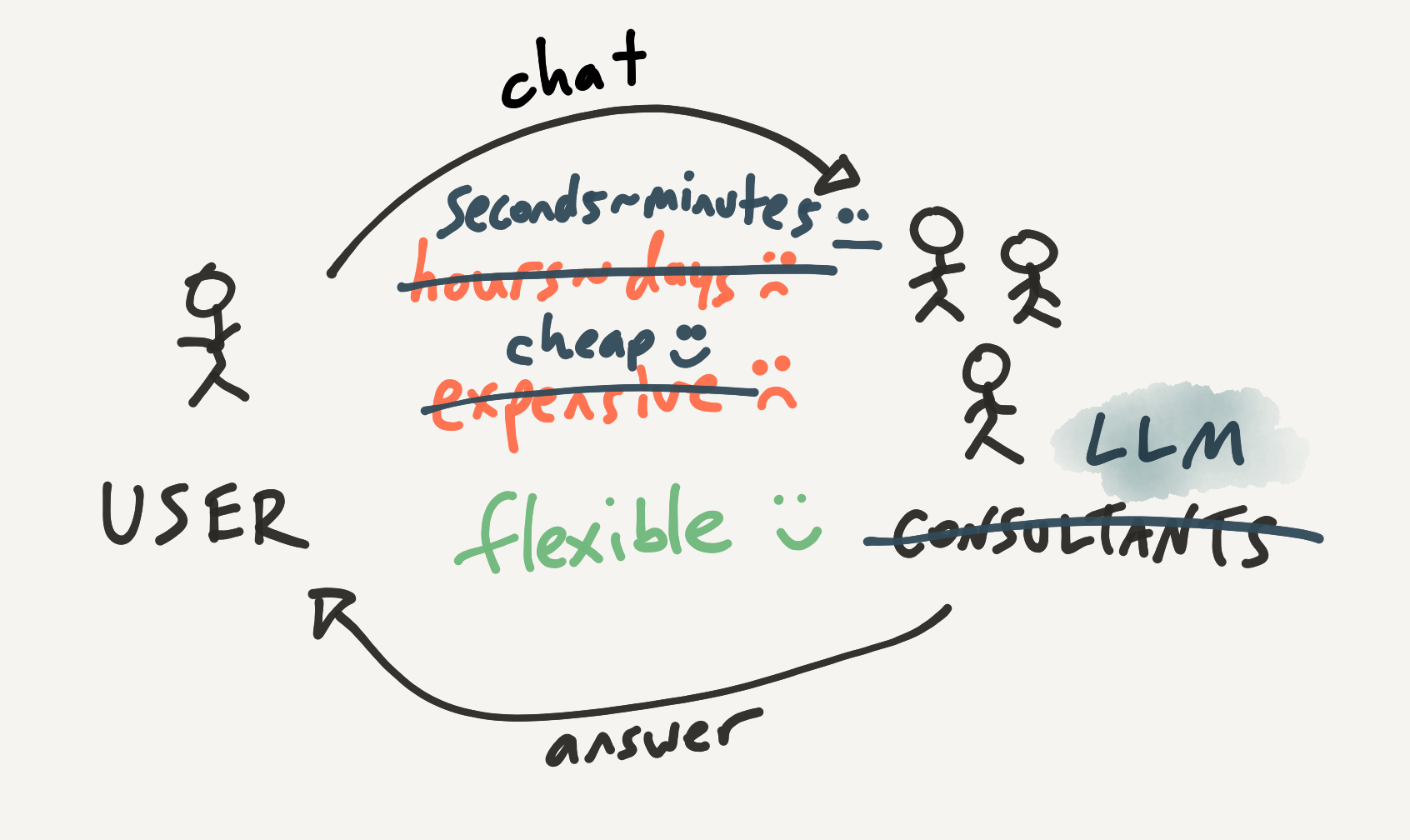
Next, consider LLMs applied to the app model. What if we started with an interactive analytics application, but this time we had a team of LLM developers at our disposal? As a start, we could ask the LLM questions about how to use the application, which could be easier than reading documentation.
But more profoundly than that, the LLM developers could go beyond that and update the application. When we give feedback about adding a new feature, our request wouldn't get lost in an infinite queue. They would respond immediately, and we'd have some back and forth to get the feature implemented. Of course, the new functionality doesn't need to be shipped to everyone; it can just be enabled for our team. This is economically viable now because we're not relying on a centralized team of human developers to make the change.
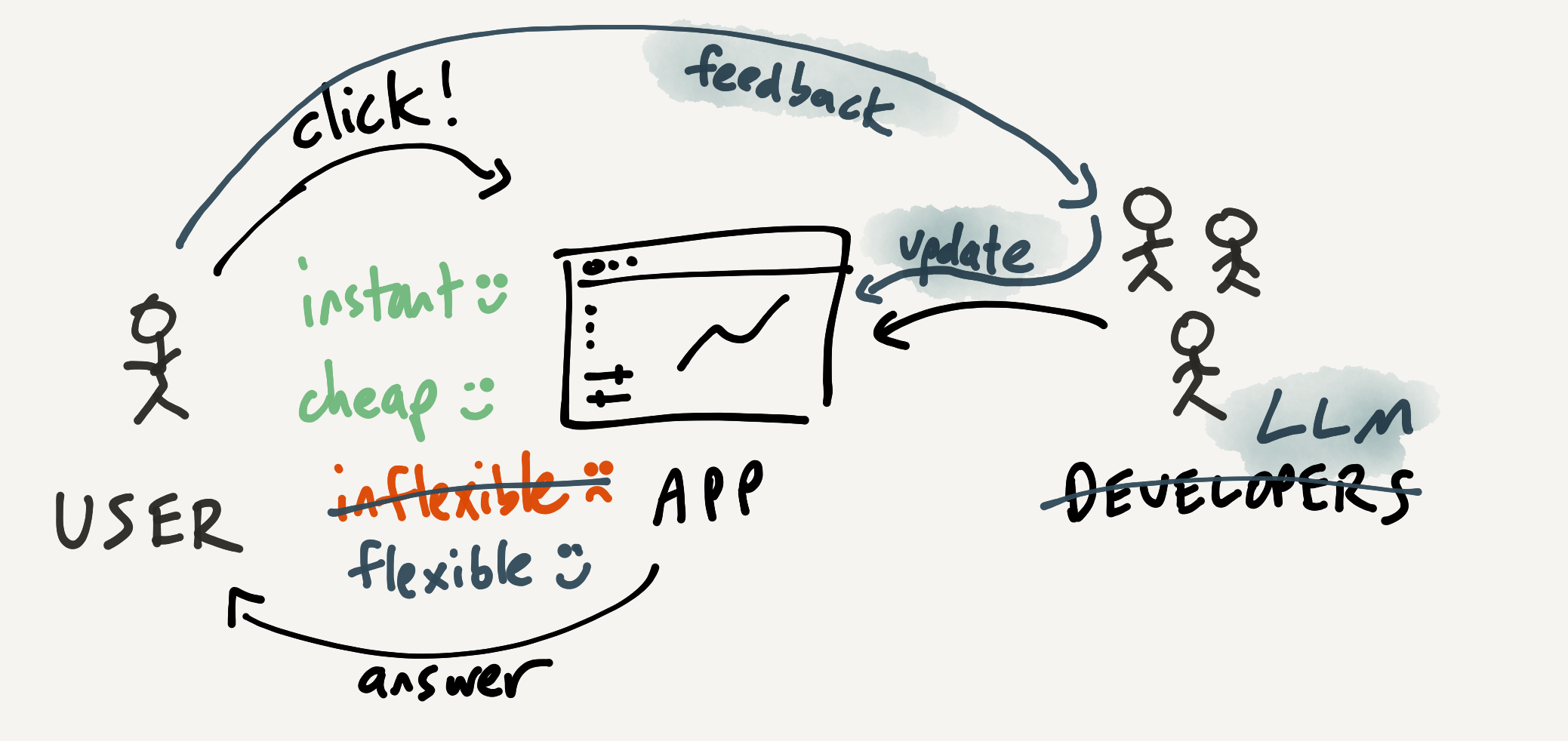
Note that this is just a rough vision at this point. We're missing a lot of details about how this model might be made real. A lot of the specifics of how software is built today make these kinds of on-the-fly customizations quite challenging.
The important thing, though, is that we've now established two loops in the interaction. On the inner loop, we can become one with the tool, using fast direct manipulation interfaces. On the outer loop, when we hit limits of the existing application, we can consciously offer feedback to the LLM developers and get new features built. This preserves the benefits of UIs, while adding more flexibility.
From apps to computational media
Does this double interaction loop remind you of anything?
Think about how a spreadsheet works. If you have a financial model in a spreadsheet, you can try changing a number in a cell to assess a scenario—this is the inner loop of direct manipulation at work.
But, you can also edit the formulas! A spreadsheet isn't just an "app" focused on a specific task; it's closer to a general computational medium which lets you flexibly express many kinds of tasks. The "platform developers"—the creators of the spreadsheet—have given you a set of general primitives that can be used to make many tools.
We might draw the double loop of the spreadsheet interaction like this. You can edit numbers in the spreadsheet, but you can also edit formulas, which edits the tool:
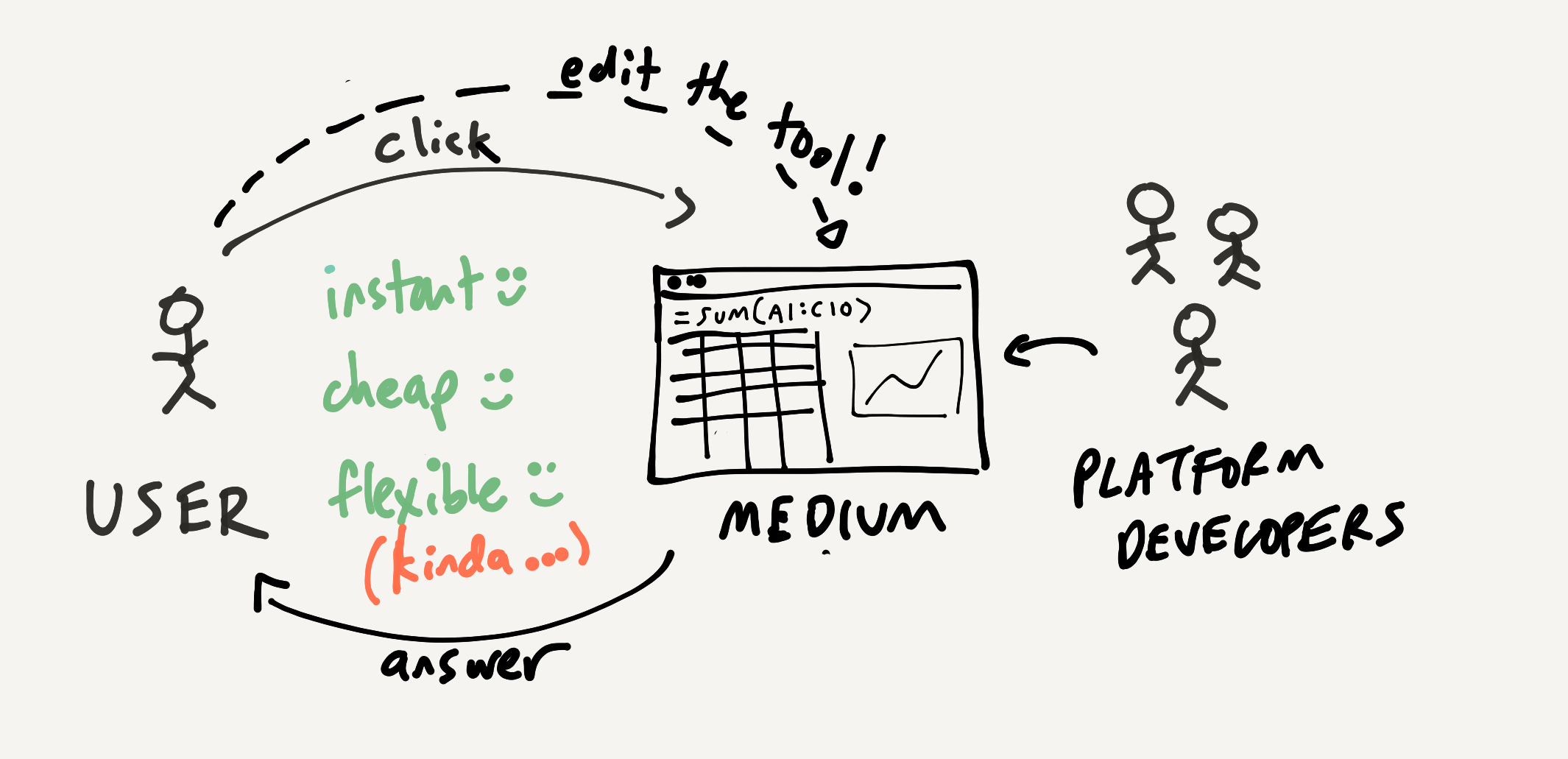
So far, I've labeled the spreadsheet in the above diagram as "kinda" flexible. Why? Well, when any individual user is working with a spreadsheet, it's easy for them to hit the limits of their knowledge. In real life, spreadsheets are actually way more flexible than this. The reason is that this diagram is missing a critical component of spreadsheet usage: collaboration.
Collaboration with local developers
Most teams have a mix of domain experts and technical experts, who work together to put together a spreadsheet. And, importantly, the people building a spreadsheet together have a very different relationship than a typical "developer" and "end-user". Bonnie Nardi and James Miller explain in their 1990 paper on collaborative spreadsheet development, imagining Betty, a CFO who knows finance, and Buzz, an expert in programming spreadsheets:
Betty and Buzz seem to be the stereotypical end-user/developer pair, and it is easy to imagine their development of a spreadsheet to be equally stereotypical: Betty specifies what the spreadsheet should do based on her knowledge of the domain, and Buzz implements it.
This is not the case. Their cooperative spreadsheet development departs from this scenario in two important ways:
(1) Betty constructs her basic spreadsheets without assistance from Buzz. She programs the parameters, data values and formulas into her models. In addition, Betty is completely responsible for the design and implementation of the user interface. She makes effective use of color, shading, fonts, outlines, and blank cells to structure and highlight the information in her spreadsheets.
(2) When Buzz helps Betty with a complex part of the spreadsheet such as graphing or a complex formula, his work is expressed in terms of Betty's original work. He adds small, more advanced pieces of code to Betty's basic spreadsheet; Betty is the main developer and he plays an adjunct role as consultant.
This is an important shift in the responsibility of system design and implementation. Non-programmers can be responsible for most of the development of a spreadsheet, implementing large applications that they would not undertake if they had to use conventional programming techniques. Non-programmers may never learn to program recursive functions and nested loops, but they can be extremely productive with spreadsheets. Because less experienced spreadsheet users become engaged and involved with their spreadsheets, they are motivated to reach out to more experienced users when they find themselves approaching the limits of their understanding of, or interest in, more sophisticated programming techniques.
So, a more accurate diagram of spreadsheet usage includes "local developers" like Buzz, who provide another outer layer of iteration, where the user can get help molding their tools. Because they're on the same team as the user, it's a lot easier to get help than appealing to third-party application or platform developers. And most importantly, over time, the user naturally learns to use more features of spreadsheets on their own, since they're involved in the development process.
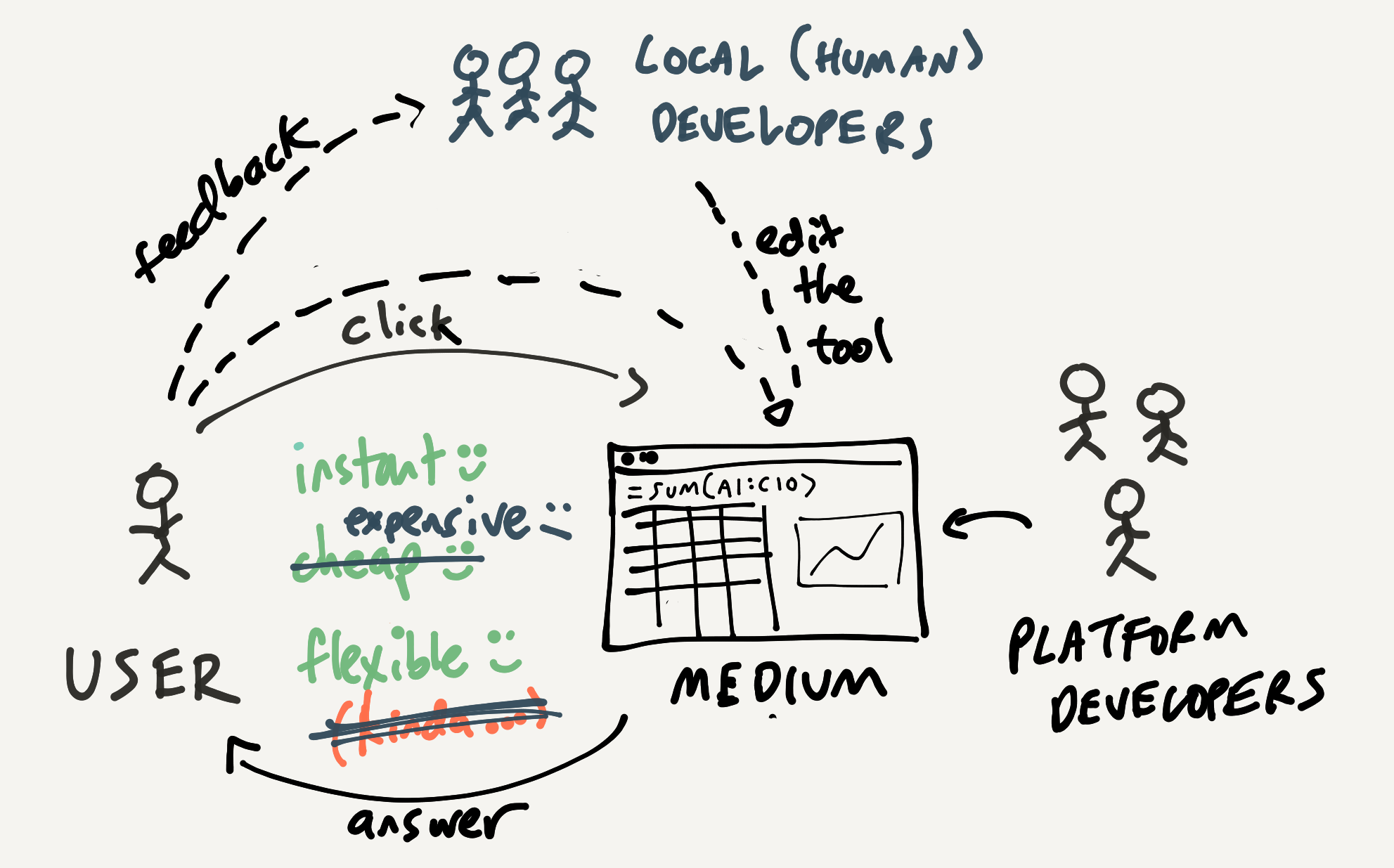
In general, the local developer makes the spreadsheet more flexible, although they also introduce cost, because now you have a human technical expert in the mix. What if you don't have a local spreadsheet expert handy, perhaps because you can't afford to hire that person? Then you're back to doing web searches for complex spreadsheet programming...
In those cases, what if you had an LLM play the role of the local developer? That is, the user mainly drives the creation of the spreadsheet, but asks for technical help with some of the formulas when needed? The LLM wouldn't just create an entire solution, it would also teach the user how to create the solution themselves next time.
This picture shows a world that I find pretty compelling. There's an inner interaction loop that takes advantage of the full power of direct manipulation. There's an outer loop where the user can also more deeply edit their tools within an open-ended medium. They can get AI support for making tool edits, and grow their own capacity to work in the medium. Over time, they can learn things like the basics of formulas, or how a VLOOKUP works. This structural knowledge helps the user think of possible use cases for the tool, and also helps them audit the output from the LLMs.
In a ChatGPT world, the user is left entirely dependent on the AI, without any understanding of its inner mechanism. In a computational medium with AI as assistant, the user's reliance on the AI gently decreases over time as they become more comfortable in the medium.
If you like this diagram too, then it suggests an interesting opportunity. Until now, the design of open-ended computational media has been restricted by the programming bottleneck problem. LLMs seem to offer a promising way to more flexibly turn natural language into code, which then raises the question: what kinds of powerful computational media might be a good fit for this new situation?
Next time: extensible software
That's it for now. There are a lot of questions in the space that we still haven't covered.
Next time I plan to discuss the architectural foundations required to make GUI applications extensible and composable by people using LLMs.
Related reading
- LLM Powered Assistants for Complex Interfaces by Nick Arner
- "The fact that they generate text is not the point" by @thesephist
- "GPT-3 as a universal coupling" by Matt Webb
- "tools vs machines" and "interpreter vs compiler"