Microcosmographia xxix: Siri Teaches Interaction Design, part ii
I’m working through my music library in chronological order, which has been a thrilling rediscovery of my favorite music in its original context. When 1975 came around, I asked Siri to cue up a Soft Machine album and the resulting failure was another fascinating lesson in interaction design, in the spirit of my original Siri Teaches Interaction Design post. Let’s dissect it!
The oldest user interfaces are command-lines — textual dialogs with a system that pedantically interprets everything exactly as you type it, and gives up entirely if you type something it doesn’t understand. They’re gloriously unambiguous, but require you to learn their hyper-precise, utterly unnatural language.
In contrast, conversational interfaces like Siri (and Cortana and Google Now) make that compromise the other way around: much more ambiguous, but with almost no special language to learn at all. Just speak your native language! All the pressure of making a computer understand a human is taken off of you and shifted onto the poor designers and engineers. Their first colossal challenge is recognizing your voice — what did you say? Can it hear you in a noisy room? How about if you’re one of the millions of people who mix languages in their daily life, or you want to contact someone with an uncommon name? What if you have an accent? Then, once they’ve got the words they think you said, comes the job of interpreting them — what did you mean?
This is probably an artificial general intelligence problem: the day we finally solve it is probably also the day that we birth a superintelligence that hopefully won’t kill us all. Until then, the best we can do is to put together fuzzy systems that use context and a library of prior knowledge to weight possibilities and ultimately guess what your words probably mean.
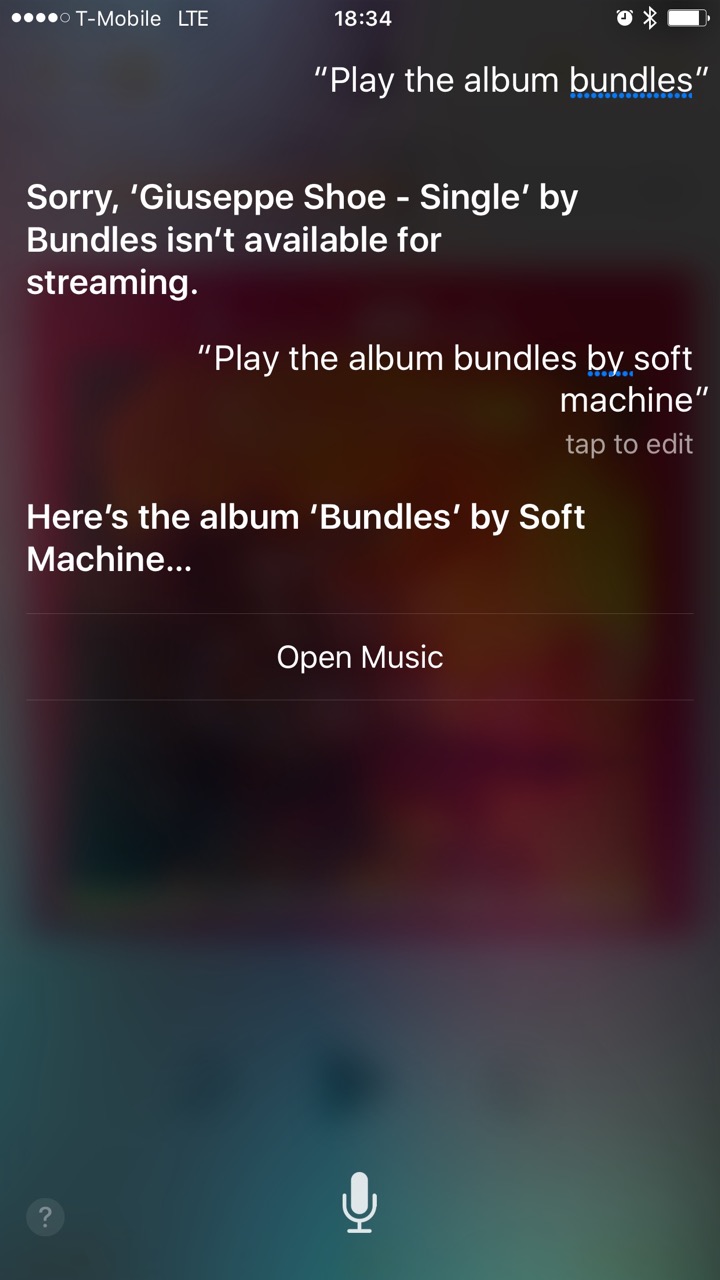
Anyway, that Siri failure. I figured that asking for the album Bundles would be good enough, considering that I only have one album by that name in my music library. Instead I got a single from an artist I’d never heard of, and it couldn’t even play. What surprised me about the result was how many distinct prioritization steps it seems not to have done:
- Match the type of data I specifically asked for: the album, not the artist. This isn’t even fancy fuzzy logic; it’s just a good old-fashioned database query. When the user generously specifies both the field and the value, use it!
- Prioritize my own data over random data out there in the cloud. I’ve gone to the trouble of adding my favorite music to my iTunes library; it seems that Siri should look for matching results in that generous trove of user-specific meaningful context first.
- Prioritize data that I have an established relationship with. In addition to having them in my personal library, I’ve also told the Apple Music online service that I really like Soft Machine by streaming their music and by hitting the Like button many times. The band called Bundles, on the other hand, I’ve never heard of, let alone listened to in iTunes.
- Prioritize data that is actually available. Even ignoring all of the above, if the first matching result isn’t available to stream, how about continuing until you find something that is?
- Model the metadata that’s important to people who use the data. iTunes doesn’t know the difference between an album and a single, even though it’s a very meaningful distinction for music fans. Instead they encode the nature of the release into the title, tacking on the word “Single”. If the software understood the distinction, it could notice that this “Giuseppe Shoe” release is a single, and I asked for an album, scoring another point in favor of the correct result.
- Recognize the popularity of the data. This should be a last resort, because there are so many delicious bits of context, particular to the user, that should get you to the correct result. A huge benefit of personalized systems is that they can know what you prefer, no matter how common your preferences are. But say if the user asks to hear the song “Hello”, and there’s a super-hot single out just this week by that name? In the absence of any data, play the hot one, not any of the hundreds of other songs out there by that name.
Not making any of these prioritizations suggests that what’s actually going on in this system is an old-fashioned, linear, command-line-like process: Do a music search; get the results; pass the first result to the player; if something goes wrong, return an error and give up. But a conversational interface demands a more organic, probabilistic process: Do a search; get the results; weight the results based on context and prior knowledge; try the best match; if something goes wrong, go back and try something else.
Thank You and Be Well
Thank you. Be well!