You might want to pay attention to Polars - our first thoughts
You might want to pay attention to Polars - our first thoughts
Further below are 4 jobs including Lead and Senior Data Science positions at companies like JustEat and ECMWF...
Below I talk on my Rebel AI leadership group (could this support you? I'd like to hear!), some schedule details for PyDataLondon 2023, my first thoughts on Polars over Pandas 2 (Arrow + Query planner == great!), Martin's article on "the Alan Turing institute has failed", my JustGiving endeavour for later in the year and updates on DirtyCat, DTreeViz, SpaCy and Numba.
Rebel AI leadership group (a forthcoming endeavour)
During my strategic consulting with teams I've repeatedly noted that higher level leadership questions keep coming up. Whilst I've got "Ian's answers" I can't help but think that a broader leadership group would have even better answers. To that end I'm building Rebel AI - a private leadership group for the top data science leaders in my network. I'm curating this group, it is a paid thing for those who want to deliver impactful data science results faster.
I'm looking for leaders who are having trouble shipping high value data products to their organisation, you're probably also a bit frustrated. You've already tried various approaches and things aren't getting easier. You want the advice of a trusted set of peers - "fresh eyes" and some validation of your strategies. This is less about "which ML model to choose" and far more about "am I tackling the right strategic problem?".
This newsletter will continue (and remains free - nothing changes). My courses continue, as will my conference talks and open sessions like the Executives at PyData discussion groups at our PyData conferences. Rebel AI is an addition to my professional services to help a wider group of leaders get valuable systems shipping and making a difference.
Reply to this email if you'd like to hear more and tell me what you want help with and we can have a call. I've got a one-pager description and I'd be keen to talk about your current frustrations.
I've mostly wrapped up with 2 clients this year with great success with unblocking processes, figuring out where the value really is and doubling-down to get value unlocked. It has been a lot of fun (and worth a few million between the clients) and I'm keen to dig more into this. There's also a reflection in the software engineering tools below on this.
PyDataLondon 2023 conference and getting your questions answered in the open PyDataUK slack
In a week on June 2-4 our PyDataLondon 2023 conference will run in central London near Tower Bridge. The schedule is up with tutorials on TensorFlow, Active Learning, MLFlow and plenty more followed by talks on Code Smells, Large Scale Agent Based Simulations (Virgin for fibre routing), Multi-armed Bandits, Green-optimised compute, Polars vs Pandas, dbt, time series and loads more (with a few slow-to-confirm speakers to be filled in shortly).
Note that we have a NEW VENUE, close to the old one, but do check the address
Tickets are selling and sponsorship slots can still be available if you'd like to reach 400+ excellent data science and engineering folk. If you're in our meetup group you'll have seen my conference announce.
We would love it if you could share details about the conference with your network - post-Covid a lot of folk are travelling less, so we need a bit more help reaching those who'd love to attend. Can you help us please? Our PyDataLondon organiser crew are all volunteers (9 years+ for me as a founder). Here's a tweet and toot to reshare, or please post into LinkedIn and elsewhere - all help appreciated.
Personally I'll be running another of my Executives at PyData discussion sessions for leaders. This is related to the Rebel AI leadership group I noted above, but the session at the conference is open to all attendees and will be written-up and shared after. Reply if you'd like to get on my GCal calendar invite as a reminder.
We have a couple of other discussion sessions too - after Giles and I talk on "Pandas 2 vs Polars vs Dask" we'll have an open discussion session on "Higher Performance Python" - come ask your questions and share what's working (or not) for you. There is also a "Teach data science better" discussion session and another on "'GDPR 2' - CRA". For Sunday lunch we have a PyData Organisers Lunch.
If you'd like to be in the company of 1k+ PyData UK meetup members (I figure many of you here are also in PyData) then join here, the slack is free and friendly.
First thoughts on Polars
Giles Weaver and I will be talking at PyDataLondon on Pandas 2, Polars or Dask?. There's been a lot of change recently in the ecosystem for small- and medium-data (i.e. that which fits on disk but not ram) and we're giving a review on what we see.
Pandas 2 introduces PyArrow as a first-class datatype, so you don't have to depend on NumPy for your backend data. Is this a good thing? Well - it seems to be. Arrow generally stores data in the same space or less space and the specification is cross-platform (so you could share without copy to tools in R or elsewhere). Notably Strings are much more efficiently stored with Arrow, taking far less room (maybe 10x less room) than in NumPy arrays, if you have repetition in the data.
Pandas 2 also introduces Copy on Write, so you only get copies of Series or DataFrames when a modification is being made. In Pandas 1.5 you could easily get copies inadvertently, leading to memory bloat. I have no idea how this plays out (the CoW feature only being turned on recently), but it looks like it isn't doing anything bad and does lead to lower RAM usage.
Polars is the relatively new competitor to Pandas. It was initially designed for in-RAM (small) data only, and recently was extended for medium (on-disk) data on a single machine. Giles and I have been very impressed, the learning curve isn't too bad and I've had up to 10x improvements in complex operations in-ram compared to Pandas (e.g. a filter, groupby, agg) on 100M row datasets.
The speed improvements come about because Polars includes a Query Planner - it can simplify a chained sequence of operations to significantly reduce computation, and it can run parts of the sequence across multiple cores. Pandas generally lacks both of these benefits.
Polars also has rough edges but the core development team are quick to fix them (e.g. this one). The Discord is active and frankly the learning curve really hasn't been an issue. I'm pretty impressed. Matplotlib and Seaborn work - we have demos of all of this for our PyDataLondon talk, plus timings against Pandas with NumPy and Pandas with Arrow.
The syntax is a bit harder to read perhaps and a bit more verbose (but Giles reminds me that it is very PySpark-like), but the scope for "many ways to do it" is far reduced compared to Pandas, so once you've figured out your query then generally you know what you need to do.
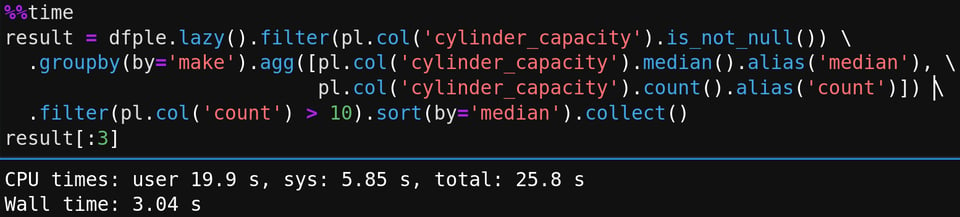
In the above I've turned an eager (already in-memory) dataframe into a lazy one, then specified a query, the asked to collect the results. This is roughly 10x faster than my equivalent Pandas+PyArrow result (and Pandas+NumPy is slower again).
One downside is that scikit-learn support is weak (as in - you can't use many of the tools in sklearn, but the base estimators work). Details here, here and here.
Dask of course is the "older sibling" and handles bigger-than-RAM Pandas, bigger-than-1-machine Pandas, and NumPy and plenty more. We've compared some of our medium-data operations between Polars' streaming mode and Dask and again we're nicely impressed.
Directly after our talk we'll be having a discussion session on Higher Performance, I'd love it if you're attending to the conference for you to attend and share your insights.
"The Alan Turing Institute has failed to develop modern AI in the UK"
My friend Martin Goodson (founder of EvolutionAI and Chair for the Royal Statistical Society's DS section) has published a provocative piece on how the Alan Turing institute has failed in the UK, the hn discussion is pretty interesting.
I'd generally say I agree. I know of a couple of projects that were supported by the Alan Turing institute (but existed before), I haven't seen anything created there, and nothing over a bunch of years has really caught my attention.
The quote from Rich Sutton in the hn thread caught my eye (from a bitter lesson):
"The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin. The ultimate reason for this is Moore's law, or rather its generalization of continued exponentially falling cost per unit of computation. Most AI research has been conducted as if the computation available to the agent were constant (in which case leveraging human knowledge would be one of the only ways to improve performance) but, over a slightly longer time than a typical research project, massively more computation inevitably becomes available.
Seeking an improvement that makes a difference in the shorter term, researchers seek to leverage their human knowledge of the domain, but the only thing that matters in the long run is the leveraging of computation. These two need not run counter to each other, but in practice they tend to. Time spent on one is time not spent on the other. There are psychological commitments to investment in one approach or the other. And the human-knowledge approach tends to complicate methods in ways that make them less suited to taking advantage of general methods leveraging computation."
Martin's suggesting that the UK Government redirect money and efforts to focus on open source support of LLMs and to avoid having a committee of non-domain-experts in charge. I'd love to believe that the UK Government can spend money wisely on AI efforts but I rather think that the decision makers are so far removed, there's little chance of useful action occurring.
And now for something different - raising money for Parkinson's Research
This is a personal note unrelated to data science. Well, sort of - I will be talking about data for this (as noted above) for our PyDataLondon 2023 talk. Later in the year I'm taking part in a charity car drive, we'll be raising money for charity - if you'd like to make the world a better place, please donate here. I will be humbled if you'd donate. You might want to donate because you've lost a loved one, because you benefit from what I write, because you like the idea of a silly car adventure or just because you haven't donated anywhere for a while and maybe it is time to balance the karmic books. However it works for you, I'd love to receive a donation.
If you know me enough to drink beer with me I might tell you about the misadenture of buying our first "banger car" that met the event's criteria. It ended with a fire engine (but thankfully just a lot of smoke). It turns out buying a banger that works is a bit of a challenge. This story will develop...If you'd like to see photos of the burned out car go to the JustGiving link and scroll down.
Open Source
Get ready to learn about the following upcoming/existing projects:
Dirty Cat: a Python library designed to help with machine learning on categorical variables that may contain errors or variations. It provides various tools and encoders for handling morphological similarities, typos, and variations in categorical data for eg: TableVectorizer and fuzzy_join. As of now, it does not support semantic similarities, which involve understanding the meaning of words or phrases.
Dtreeviz: This library enables visualization and interpretation of decision trees, which are key components of gradient boosting machines and Random Forests. The visualizations are inspired by educational animations and aim to aid understanding and interpretation of these models. It supports various machine learning frameworks (such as scikit-learn, XGBoost, Spark MLlib, LightGBM and TensorFlow)
Spacy: It’s a free and open-source project (supported by Explosion, a software publishing company) for advanced Natural Language Processing (NLP) tasks in Python. It helps you process and understand large amounts of text, extract information, and perform tasks like language understanding. SpaCy is designed for production use and provides efficient text processing capabilities based on the latest research.
Numba: An optimizing compiler for Python (supported by Anaconda, Inc.) that enables faster execution of numerical computations. By leveraging the LLVM compiler project, Numba can generate efficient machine code from Python syntax and compile a significant portion of numerically-focused Python code, including numerous NumPy functions. It offers additional features like automatic parallelization of loops, the ability to generate code that runs on GPUs for accelerated computation, and the creation of ufuncs (universal functions) and C callbacks for seamless integration with other code.
Skrub (was Dirty Cat 0.4.0)
(dirty-cat has just been renamed skrub and links to old PRs seem to have disappeared so I've simplified the following - Ian)
Here's an example of looking for similarity across text names:
The SuperVectorizer functionality has been renamed as TableVectorizer; avoid using the old name so that you don’t encounter any error messages! A new experimental feature called fuzzy_join() allows tables to be joined by matching approximate keys - it finds matches based on similarities between strings and nearest neighbours matches for each category.
FeatureAugmenter is an experimental feature that is a transformer used to augment the number of features in a main table using fuzzy_join() by assembling information from auxiliary tables to enhance the features. Some unnecessary parts of the API are made private to make sure that files, functions, classes (starting with an underscore) are not imported directly into your code. The MinHashEncoder now supports a parameter called n_jobs that enables parallel computation of the hashes to process data faster. Another new experimental feature called deduplicate() is introduced to help identify and remove duplicate categories with misspellings by clustering string distances (works best for a large number of categories).
Some minor changes include adding example Wikipedia embeddings to enhance data, using an additional argument called directory that specifies the location of datasets for fetching functions, changing the default behaviour of TableVectorizer's OneHotEncoder for low cardinality categorical variables (when encountering unseen categories during testing, it will encode them as a vector of zeros instead of raising an error) and adding get_ken_embeddings() + fetch_world_bank_indicator() in datasets.fetching module to download + filter Wikipedia embeddings and indicators from the World Bank Open Data platform respectively.
Dtreeviz 2.2.1
The pie charts in the visualization now accurately display the new data, rather than presenting the same data that the classifier was trained on. The sklearn visualizations are made to support validation datasets to provide a comprehensive view of the decision tree model's performance on new data. Different display types have been added for the x-axis of the leaf_distributions plot thus enhancing the flexibility in visualizing and interpreting the distribution of samples in leaf nodes.
Here's an example from the homepage for explaining the Iris dataset:

Some bug fixes that have been resolved include the TypeError: dict() argument after ** must be a mapping, not float error, and a different visualisation error that occurred when a decision tree node contained samples belonging to only one class - the fix ensures that the nodes are accurately represented.
Spacy 3.5 (a more comprehensive guide to this version’s updates is given here)
Three new CLI commands are added to enhances the functionality and usability of spaCy - apply (allows users to easily apply a pipeline to multiple input files and save the annotated documents, thus saving time, effort and creating a streamlining their workflow), benchmark (used to measure the speed and performance of spaCy on different datasets, facilitating performance optimization) and find-threshold (helps users fine-tune their models by identifying the optimal threshold for a given score metric).
Users can now perform fuzzy matching using the Matcher, enabling them to handle cases where exact string matches may not be possible or desired (FUZZY uses Levenshtein edit distance rather than Damerau-Levenshtein edit distance) - it’s useful for tasks such as spell checking, approximate string matching, entity recognition with tolerance for variations, and handling noisy or misspelt input data.
The knowledge base used for entity linking can now be customised and has a new default implementation called InMemoryLookupKB - In a generic sense, it’s useful for named entity recognition, disambiguation of entity mentions, linking entities to external knowledge bases or databases and enhancing the accuracy of entity-related tasks; while the specific customization option allow users to adapt the entity linking models to different domains or specialised contexts.
Language updates in Slovenian, French, Catalan, Ancient Greek, Russian, Ukrainian, and Dutch allows users working with these languages to ensure better handling of linguistic nuances, enhance tokenization and lemmatization capabilities, and expanding the overall language coverage of spaCy
Numba 0.57.0 (a more comprehensive guide to this version’s updates is given here)
Numba is now compatible with Python 3.11 and NumPy 1.24! A number of enhancements have been added for Python that include support for non-compile-time constant arguments in Exception classes (increased flexibility in error handling), workability of built-in functions hasattr and getattr with compile-time constant attributes, implementation of str and repr (enabling custom string representations for types), support for additional keyword arguments in str.startswith, support for boolean types in min and max functions and support for the dict(iterable) constructor making it easier to create dictionaries from iterable objects.
Similar for NumPy, some added features are as follows: significant enhancements to numpy.random.Generator for commonly used probability distributions, implementation of nbytes property for NumPy ndarray types, support for nested-array types, integer casting of datetime and timedelta types, support for F-order (Fortran order) iteration in ufunc generation and Several new functions are now supported (np.argpartition, np.isclose, np.nan_to_num, np.new_axis, and np.union1d).
Extensive refactoring has been done to convert many of Numba's internal implementations of Python and NumPy functions to the high-level extension API (numba.extending)
The default target for applicable functions in the extension API is now "generic," meaning they are accepted by both CPU and CUDA targets by default. The __repr__ method is now supported for Numba types (allowing customized string representations) and the use of __getitem__ on Numba types enables more flexible array indexing.
To improve overall performance methods like str.find() and str.rfind() can be used for string searching, numba.typed.Dict can be used to allocate a predetermined initial size (reducing the need for resizing) alongside utilising Numba Runtime (NRT) for better performance and safety, including optimized statistics counters, improved cache line filling, faster import speed, and enhanced allocation calls.
The CUDA improvements include support for new NVIDIA hardware and software (CUDA 11.8 and 12, Hopper, Ada Lovelace, and AGX Orin).
Float16 arithmetic operations are now fully supported, with added methods for checking float16 compatibility. The high-level extension API is now fully supported in CUDA, allowing for expanded capabilities of CUDA-accelerated functions. Eager compilation, multiple signatures, multiple outputs, and specifying return types of generalised ufuncs are now possible in CUDA.
Additionally, a limited set of NumPy ufuncs, specifically trigonometric functions, can be called inside CUDA kernels. Lineinfo quality has been improved, ensuring accurate line information during debugging without affecting generated code. Version support and dependency changes like making the setuptools package optional, requiring TBB threading layer version 2021.6 or later, and adding support for LLVM 14 on all platforms through llvmlite, enhance compatibility with the latest versions.
Footnotes
See recent issues of this newsletter for a dive back in time. Subscribe via the NotANumber site.
About Ian Ozsvald - author of High Performance Python (2nd edition), trainer for Higher Performance Python, Successful Data Science Projects and Software Engineering for Data Scientists, team coach and strategic advisor. I'm also on twitter, LinkedIn and GitHub.
Now some jobs…
Jobs are provided by readers, if you’re growing your team then reply to this and we can add a relevant job here. This list has 1,500+ subscribers. Your first job listing is free and it'll go to all 1,500 subscribers 3 times over 6 weeks, subsequent posts are charged.
Lead Data Scientist - Experimentation and Causal Inference at Just-Eat Takeaway.com, Permanent, Amsterdam or London
We’re searching for opportunities to perfect our processes and implement methodologies that help our teams to thrive locally and globally. That’s where you come in! As a Lead Data Scientist in our Experimentation and Causal Inference team, you will work at the intersection of data science, statistics, and analytics to help build the best customer experience possible.
Enabling data-driven decision making through fast, trustworthy and reliable experimentation at scale, you will work alongside data scientists, analysts and engineers to define our experimentation pipeline which enables causal inference and automates insight extraction from hundreds of experiments. Your work will be used across every product and business function, and enable a standard way of working for causal inference across tech and non-tech functions to evaluate the impact of changes made throughout our business. As lead data scientist, it is expected that you will teach your team new tricks from a scientific perspective as well as way of working. Most importantly, your work will directly contribute to building the world’s most customer-friendly food delivery app.
- Rate:
- Location: Amsterdam or London (central)
- Contact: Please apply through the links below (please mention this list when you get in touch)
- Side reading: link, link
Senior Data Analyst (Commercial Insights) at Catawiki, Permanent, Amsterdam
We’re looking for a Senior Data Analyst / Senior Data Scientist Insights to become the Data Business Partner of our Categories (Luxury Goods, Art, Interiors, and Collectables), in close collaboration with their dedicated Finance Business Partners.
Your role will be to analyse current business trends and to derive actionable insights in order to support our categories in shifting their commercial strategy when and where needed (supply, demand, curation etc). You will be a trusted business partner for them, who is actively participating in the decision-making, and regularly identifying new business opportunities.
- Rate:
- Location: Amsterdam, The Netherlands
- Contact: j.den.hamer@catawiki.nl (please mention this list when you get in touch)
- Side reading: link, link, link
Data Scientist / Data Engineer at 10 Downing Street
The No10 data science team, 10DS, offers an unparalleled opportunity to develop your career personally through these demanding and intellectually stimulating roles. Formed in mid-2020, 10DS has a remit to radically improve the way in which key decisions are informed by data, analysis and evidence.
We are looking for exceptional candidates with great mathematical reasoning. In return you will be provided an unparalleled opportunity to develop your technical skills and support advice to help improve your country.
- Rate:
- Location: London
- Contact: avarotsis@no10.gov.uk (please mention this list when you get in touch)
- Side reading: link
Scientist/Senior Scientist for Machine Learning at ECMWF
The European Centre for Medium-range Weather Forecasts (ECMWF) is looking to hire multiple (senior) scientists for machine learning. We're now in 3 locations across Europe (with adjusted salaries), working on improving weather forecasts for Europe.
If you have experience on the traditional HPC + ML or ML + Earth Systems Science side of things, or more of a ML coordinator, you may be a great fit. Especially, if you're part of a under-represented minority, please consider that the job post is written for both senior and regular scientists and you may not have to match every single bullet point to be a great fit. Our machine learning ecosystem: a lot of deep learning from CNNs to transformers and GNNs on lots a GPUs.
The ECMWF itself is an intergovernmental organisation created in 1975 by a group of European nations and is today supported by 35 Member and Co-operating States, mostly in Europe with the world's largest archive of meteorological data. So definitely a very unique place to work and push state-of-the-art machine learning these days.